第十章 优化
本章涵盖
- 实例级优化
- 查询优化
- 表优化
- 事务隔离级别
- 通过增加硬件来解决性能问题
在本章中,我们将深入探讨与 SQL Server 性能优化相关的错误和误解。我们将从实例级优化开始,讨论已弃用的跟踪标志的使用、关于即时文件初始化的误解以及内存配置错误。错误大致有两种类型:未能优化和错误的优化。
未能优化
我最近目睹了一次优化失败。我被要求查看一个提取、转换和加载(ETL)过程,这个过程在将数据加载到数据仓库时花费了大量时间。经过对该过程的检查,很明显团队没有进行容量规划(参见第9章)。虽然磁盘还有剩余空间,但数据文件的大小并未考虑每晚被导入数据库的大量数据。这导致数据文件在每晚多次以小增量扩展。即时文件初始化没有启用,这意味着每次增加文件空间时都会被清零,这在本章讨论的第二个错误中提到。启用即时文件初始化立即解决了问题,但我也让团队去规划他们的容量并相应地调整磁盘大小。
然后我们将继续讨论在优化查询时犯的错误。其中第一个错误是在本应与优化器合作时却与其对抗。接下来我们将讨论查询处理反馈,这一点经常被数据库管理员(DBA)忽视。
我们将继续研究表优化。在这里,我们将讨论一个常见的错误,即忽视有用的性能优化技术,包括分区表和压缩表。
接下来我们将看交易隔离级别,在这里我们将探讨我一次又一次看到的错误和误解。最后,我们将讨论当我们决定通过增加硬件来解决性能问题时会发生什么。
为了讨论本章的错误,我们将使用在第6章中创建的Marketing数据库以及在第9章中创建的MarketingArchive数据库。如果您已经按照第8章的示例操作,但尚未修复MarketingArchive数据库,请在继续之前运行清单10.1中的脚本。
警告: 在正常操作中,除非没有其他恢复选项(例如从备份恢复等),否则不应使用 REPAIR_ALLOW_DATA_LOSS,因为此选项可能会导致数据丢失。
USE master ;
GO
ALTER DATABASE MarketingArchive SET SINGLE_USER ;
GO
DBCC CHECKDB (MarketingArchive, REPAIR_ALLOW_DATA_LOSS) ;
GO
ALTER DATABASE MarketingArchive SET MULTI_USER ;
GO
对于对实例进行更改的示例,任何实例都可以,但承载 MarketingArchive 数据库的实例将是一个不错的选择。
错误54# 开启 TF1117 和 TF1118
跟踪标志是允许管理员更改特定配置的切换选项。每个标志都有一个三位或四位数字,虽然许多标志未被记录或与较旧版本的 SQL Server 相关,但确实存在一些有用的跟踪标志。例如,跟踪标志 3226 可用于抑制成功备份的消息。这可以减少 SQL Server 日志中的“噪音”。
根据跟踪标志的性质,可以将配置应用于本地会话或全局,即所有会话。例如,上述的3226标志只能在全局开启。
可以使用 DBCC TRACEON 和 DBCC TRACEOFF 命令来打开和关闭跟踪标志。将跟踪标志编号传递给命令以进行会话配置。对于全局配置,则传递第二个参数 -1。例如,以下脚本演示了如何在会话中启用跟踪标志 1224,然后在全局启用。此标志会禁用基于锁数量的锁升级:
DBCC TRACEON (1224) ;
DBCC TRACEON (1224,-1) ;
全局跟踪标志的挑战在于,它们在数据库引擎服务重启后不会保留。因此,如果我们希望某个配置在重启后持续有效,必须将其作为 SQL Server 服务的启动参数添加。
前些时候,通常会使用两个这样的跟踪标志来帮助解决数据仓库类应用程序中的性能问题,以及在某些情况下 OLTP 类工作负载中的 TempDB 问题。具体而言,T1117(跟踪标志 1117 的常用缩写)用于在任何文件达到其自动增长阈值时增长文件组中的所有文件。SQL Server 使用比例填充算法在文件组中的各个文件之间分配数据。因此,同时增长所有文件可以防止 SQL Server “偏向”较大的文件,从而无法充分利用并行读取文件的数据的全部优势。
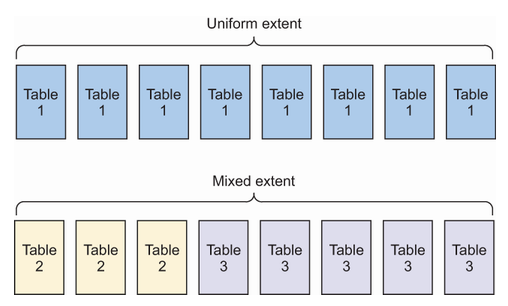
T1118用于强制统一区。 这意味着多个对象不能将页分配到同一区。默认情况下,小对象(小于64 KB)可以使用混合区。强制使用统一区有助于防止系统页(例如全局分配映射(GAM)、共享全局分配映射以及每个数据文件中存在的页空闲空间系统页)出现争用。统一区与混合区如图10.1所示。
在 SQL Server 2016 中,T1117 和 T1118 都已被弃用,其功能已被移动到更低的层级,这意味着它们可以进行更细粒度的配置。这是一种更好的实现方式,因为配置可以应用于将从中受益的特定数据库,而不需要像跟踪标志那样将配置应用于所有数据库。
我仍然看到有人在数据库引擎服务上设置 T1117 和 T1118,甚至 Azure SQL Server 映像也配置了这些标志。然而,这是一个错误,因为自 SQL Server 2016 起,这些跟踪标志已经没有效果了。不清楚这一变化的管理员认为他们已经配置了这些设置,实际上并没有。
幸运的是,现在 TempDB 的文件均等增长是默认行为,但对于数据仓库仍应进行配置。统一区块现在是 TempDB 和用户数据库的默认行为。但这只是把问题反过来了。一位不清楚这些变化但希望使用混合区块和/或均等文件增长的数据库管理员,如果什么都不做,就会在不知情的情况下使用了默认的不希望的行为。
如果我们想要更改特定数据库的行为,那么我们应该做什么,而不是配置这两个跟踪标志呢?示例 10.2 中的脚本为 MarketingArchive 数据库开启了相等的文件增长,并关闭了统一区。脚本中的第一个命令使用 ALTER DATABASE..MODIFY FILEGROUP 来开启 AUTOGROW_ALL_FILES,这会覆盖 AUTOGROW_SINGLE_FILE 的默认设置。在第二条语句中,我们使用 ALTER DATABASE SET 选项来启用混合区。
ALTER DATABASE MarketingArchive
MODIFY FILEGROUP [PRIMARY] AUTOGROW_ALL_FILES ;
ALTER DATABASE MarketingArchive
SET MIXED_PAGE_ALLOCATION ON ;
提示: 这些命令也可以通过期望状态配置来执行(参见第8章)。
错误55# 未使用即时文件初始化
当 SQL Server 创建文件或扩展文件时,它必须将文件清零,这字面意思是用 0 填充任何空白空间。作为性能优化,可以通过使用瞬时文件初始化来跳过数据文件,有时也可以跳过事务日志文件的这一过程。为此,我们只需将运行数据库引擎服务的服务帐户赋予“执行卷维护任务”用户权限(SeManageVolumePrivilege)。SQL Server 就会在文件创建或扩展时自动跳过清零过程。微软在最近版本的 SQL Server 中更是简化了这一操作,在安装过程中将其作为一个选项提供。同时,它也将其作为一个选项添加到 SQL Server 配置管理器中数据库引擎服务的高级选项卡中,如图 10.2 所示。
所以启用这个看起来似乎是显而易见的,对吧?嗯,并不完全如此,我看到一些数据库管理员犯的错误就是选择不去实施它。要理解为什么有些数据库管理员会犯这个错误,我们需要了解其安全影响。
想象一下我们有一个包含非常敏感信息的数据库。该数据库被迁移到新的服务器上,并且从原服务器上删除。然后,原服务器被用来托管一个新的数据库。
当数据从磁盘中被删除时,物理数据并没有被删除——只有指向该数据的指针被删除。当在磁盘的同一物理位置创建新的数据文件时,文件会被清零,因此原始数据会被覆盖。
在使用即时文件初始化的情况下,数据不会被覆盖,直到 SQL Server 在相同的物理位置分配区段并写入页。因此,理论上存在一个风险,即不法分子可能会检索到原始数据。
如果存在潜在的安全风险,为什么我还会建议不使用即时文件初始化是一种错误呢?答案很简单,因为风险太小,不足以抵消使用该功能的优势。
为了实现安全风险,必须满足以下所有条件:
- 磁盘上以前存在敏感数据。
- 攻击者已获得服务器的提升权限。
- 攻击者拥有查找和检索数据所需的专业软件和技能。
- 攻击者有时间在之前找到并获取数据
- 管理员注意到了攻击。
- 数据被新数据覆盖。
因此,除非你一直在储存核武器装备代码以及罗斯威尔事件的真相(并且决定之后不销毁这些光盘),否则在性能提升的背景下,这种风险可能太小,不值得担心。
错误56# 未为其他应用程序留出足够的内存
我想许多读者在看到本节标题时可能都会仔细看两次。肯定有人会认为我应该写关于在与 SQL Server 实例相同的服务器上托管其他应用程序是一个错误,而不是谈论其他应用程序的内存分配问题?
嗯,是的,在同一台服务器上安装其他应用程序与 SQL Server 一起使用是一种糟糕的做法,原因很多,包括安全性、工作负载混合以及故障排除。因此,我绝不会提倡这样做。然而,你可能没有意识到的是,SQL Server 堆栈中的其他功能,例如 SQL Server 集成服务(SSIS)和 SQL Server 分析服务(SSAS),从本质上来说也是其他应用程序。它们有自己的服务,在自己的进程中运行,并拥有自己的内存分配。因此,如果我们使用这些功能中的任何一个,那么我们应该单独考虑它们的内存需求,而不是只考虑数据库引擎。
除此之外,我们还应该考虑可能被其他团队使用的代理,例如杀毒代理、监控代理或资产管理代理,仅举几例。虽然这些代理不是面向业务的,但它们对更广泛的业务非常重要,并且通常要求安装在所有服务器上。当然,这些工具和代理应该是轻量级的,但我见过其中一些占用的内存远超预期。
我们还需要考虑留给操作系统的可用内存量。微软建议为 Windows 保留 25% 的内存。这 25% 的内存也被一些 SQL Server 组件使用,如扩展存储过程和可执行文件。
默认情况下,当您安装 SQL Server 时,实例会为缓冲池分配所需的所有内存,缓冲池是用于缓存数据页和索引页的内存区域。一个常见的错误是,数据库管理员会保留这个默认配置,理由是 SQL Server 是服务器上唯一安装的应用程序,因此它应该使用尽可能多的内存。当然,这并没有考虑前面讨论的需求。如果已经配置了“内存锁页”(Lock Pages In Memory),错误会更大,因为正如下一节所讨论的,这将阻止工作集被削减。
因此,我们应该使用以下公式配置缓冲池可以使用的最大内存量:
最大内存 = (服务器内存 – 其他进程所需内存) / 100 × 75
我们可以使用 sp_configure 存储过程来配置最大内存。列表 10.3 中的脚本将最大服务器内存配置为 48 GB,这对于单一的 SQL Server 实例来说是合适的,该实例是唯一运行在拥有 64 GB 内存的服务器上的应用程序。当然,如果服务器上运行多个实例,那么我们应该根据它们的需求在它们之间适当分配这 48 GB 内存。
提示:列表 10.3 中的值以 MB 为单位。
sp_configure ‘show advanced options’, 1 ;
RECONFIGURE ;
GO
sp_configure ‘max server memory’, 49152 ;
RECONFIGURE ;
GO
我们应该始终配置最大内存设置,以确保为操作系统留下足够的内存。虽然我们应该始终避免在托管 SQL Server 实例的服务器上安装其他应用程序,但在配置最大内存时,我们应考虑 SQL Server 堆栈中其他功能的内存需求,例如 SSIS 和 SSAS。我们还应考虑必须在服务器上运行的必需工具和代理的要求。
错误57# 未将页面锁定在内存中
如果 Windows 内存不足,它可能会变得不稳定,并且可能会出现内存不足错误。在这种情况下,Windows 会尝试通过修剪用户进程的工作集来自我保护。换句话说,它会导致进程将数据分页到磁盘,并回收内存给自己使用。
假设我们有一个资源受限的 SQL Server 实例,用户开始抱怨严重的性能下降,包括查询超时。DBA 调查该问题并在 SQL Server 日志中发现以下消息:
A significant part of SQL Server process memory has been paged out. This
may result in a performance degradation. Duration: 0 seconds. Working set
(KB): 6081740, committed (KB): 17175674, memory utilization: 35%.
此错误表明缓冲区缓存的一部分已被刷新到磁盘,内存已被操作系统回收。那么,将页面锁定在内存中是不是显而易见的选择?实际上,社区中对此有相当多的争论,这导致许多数据库管理员没有配置此设置。为什么会有争议呢?
在早期版本的 Windows Server 中,操作系统在修剪工作集时非常激进。随着时间的推移,这种行为变得不那么激进,同时内存管理总体上得到了改善。这意味着问题发生的几率减少了。
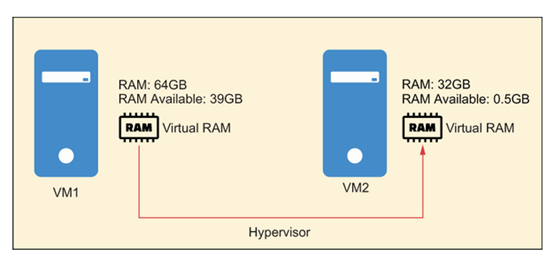
与此同时,虚拟化平台成为托管 SQL Server 的默认环境。虚拟化平台(如 VMware 或 Hyper-V)的主要好处之一是能够超额分配物理资源。这意味着,例如,一个拥有 8 个 CPU 和 64 GB 内存的虚拟化主机,可以托管总需求为 16 个 vCPU 和 96 GB 内存的虚拟机。
虚拟机管理程序通过在虚拟机需要时分配资源来管理这一过程。当资源未被使用时,它会回收这些资源并将其分配给更需要它们的其他虚拟机。这个过程被称为气球技术,如图10.3所示。
如果虚拟机正在承载锁定内存页的 SQL Server 实例,那么这些内存将无法被回收,这可能会导致整个虚拟化环境的性能问题。
关于虚拟机的论点是完全合理的,当我们在虚拟环境中运行 SQL Server 时,我们应该与 VMware 管理员密切合作,以确保我们能够为用户提供可靠的服务,而不影响整个系统。然而,关于减少工作集修剪的论点则不足以成为不将“锁定内存页”配置为默认安装选项的理由。发生频率较低并不意味着从未发生过,我也见过这种情况的发生。我们应该尽量避免这种情况,因为这些都是完全可以预防的中断。
随着云成为托管 SQL Server 工作负载的标准,也值得一提的是,主要的云提供商(如 AWS)建议在其环境中将“锁定内存页”配置为最佳实践。这是因为,尽管这是一个虚拟环境,云提供商并不超额分配资源。因此,不需要考虑气球内存机制。
通过将 SeLockMemoryPrivilege 用户权限分配给运行数据库引擎服务的服务帐户来配置在内存中锁定页面。它还可以在 SQL Server 安装期间配置,或从 SQL Server 配置管理器中数据库引擎服务的高级选项卡进行配置。
错误58# 与优化器作对
T-SQL 是一种描述性语言。这意味着,当开发人员编写查询时,他们描述的是希望 SQL Server 返回的结果,而不是给 SQL Server 提供执行当前任务的逐步指令。然后,查询优化器会计算出返回开发人员所需数据的最有效方式。
查询优化器非常复杂,并且基于索引、统计信息以及其他许多因素做出许多良好的决策。然而,它并非无懈可击,如果它选择了次优的执行计划,可能会对查询性能产生负面影响。
SQL Server 开发人员和管理员可以通过使用查询提示来影响生成的查询计划。这些提示将覆盖优化器想要做出的决策。它们应仅在特殊情况下使用,但在解决性能问题时可能非常有价值。
警告: 查询提示应仅在特殊情况下使用。大多数情况下,优化器能够正确处理。
我看到人们在使用查询提示时犯的错误是过于规定性,或者用我喜欢说的话来说,就是与优化器作对,而我们应该与它合作。最好的例子是一个提示,可以用来指定表之间应该发生的物理连接操作。
如果我们执行连接操作,例如在两个表之间进行 INNER JOIN 或 OUTER JOIN,那么查询优化器可以使用四种物理操作符来执行该逻辑操作。每种操作符在不同场景下都是最有效的选择。每种操作符在表 10.1 中进行了总结。
| Operator | Description | Most efficient use |
| Nested Loops | Choose one table as the outer input table and the other table becomes the inner input table. For each key in the outer input table, it searches every row in the inner input table for matching key values. | Small tables |
| Hash Join | Builds a hash table in memory, with each row of the first table placed in a hash bucket, dependent on the key value. The keys of the second table are then hashed and compared to the first table on a row-by-row basis. If there is not enough memory for every row in the first table, then the operation will be performed in multiple steps. | Large tables not sorted by join key or where inputs have a big difference in row count |
| Merge Join | Checks the equality of the first key in both tables. It then compares the next row in the second table to the first row in the first table. This is similar to nested loops, but because the inputs are sorted by the join key, it can stop as soon as it finds a row in the second table that is not matched and move to the next row in the first table. | Large tables sorted by join key, where each table is a similar size |
| Adaptive Join | The query starts by using a hash join but can change to nested loops during execution if the table that populates the hash table is small enough for nested loops to be more efficient. | Queries where the input rows wildly swing and Batch Mode execution is used |
想象一个场景,其中以下列表中的查询表现不佳。
SELECT
i.ImpressionUID
FROM Marketing.marketing.Impressions i
INNER JOIN MarketingArchive.dbo.ImpressionsArchive ia
ON i.ImpressionUID = ia.ImpressionUID ;
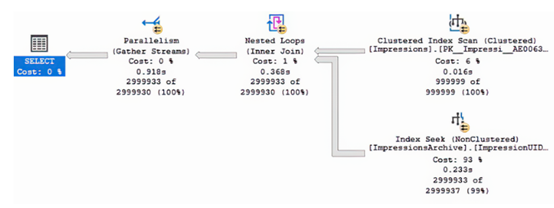
我们调查了这个问题,并在检查查询计划时发现,优化器选择使用嵌套循环作为连接操作符,如图10.4所示。在我的测试机器上,使用这个操作符运行查询需要19秒。
提示: 如果你正在跟随本章的示例,请注意,SQL Server 选择的执行计划可能与它在我的环境中选择的计划不同。
警告: 在我们继续之前,重要的是要注意,使用查询提示应当是最后的选择。这类问题通常可以通过其他方式解决,例如确保统计信息是最新的。查询提示是最后的手段。
在这种情况下,许多数据库管理员可能会犯的错误是强制优化器使用哈希连接,因为那在此时可能是最有效的选项。有多种方法可以实现这一点,包括计划冻结、查询存储提示、USE PLAN 查询提示、HASH MATCH 查询提示或连接提示。在这个示例中,我们将使用连接提示,如下列表所示。
SELECT
i.ImpressionUID
FROM Marketing.marketing.Impressions i
INNER HASH JOIN MarketingArchive.dbo.ImpressionsArchive ia
ON i.ImpressionUID = ia.ImpressionUID ;
此查询使用了图10.5中示意的计划,在我的测试设备上运行花费了5秒。
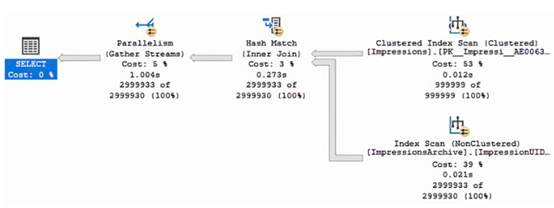
这是一个很好的结果!那么,为什么这是一个错误呢?嗯,让我们考虑一下,在这一事件之后,非聚集索引被添加到Marketing数据库表中Impressions表的ImpressionUID列,这可以通过列表10.6中的脚本实现。
提示:对于 MarketingArchive 数据库,无需创建此索引,因为我们在第9章中已经创建了合适的索引。
USE Marketing ;
GO
CREATE NONCLUSTERED INDEX ImpressionUID
ON marketing.Impressions(ImpressionUID) ;
GO
现在优化器理想情况下会选择使用新索引的合并连接,在我的测试环境中执行需要 3 秒。不幸的是,我们的提示强制优化器使用哈希连接,在我的测试环境中使用新索引执行需要 4 秒。因此,更好的方法是使用查询提示,在其中我们可以为优化器指定多个选项供其选择。请参考下一个清单中的查询。
SELECT
i.ImpressionUID
FROM Marketing.marketing.Impressions i
INNER JOIN MarketingArchive.dbo.ImpressionsArchive ia
ON i.ImpressionUID = ia.ImpressionUID OPTION (MERGE JOIN, HASH JOIN) ;
这个提示仍然排除了使用嵌套循环的可能性,我们知道由于表的大小,这永远不会是一个好主意,但它给优化器提供了选择,使用合并连接或哈希连接,取决于它判断哪种方式最有效。
尽管查询提示是最后的手段,但它们可以成为解决性能问题的有用工具。如果您决定使用查询提示,请始终尝试与优化器配合,而不是与之对抗。在可能的情况下,为优化器提供多个选项选择,而不是强行使用单一选项,因为单一选项可能会过时。
错误59# 未利用DOP反馈
在上一节中,我们探讨了如何确保在认为别无选择必须使用查询提示时,我们是与优化器协作而不是对抗优化器。如果 SQL Server 能够学习什么是最有效的并根据需要调整执行计划,生活会不会轻松得多?
SQL Server 2022 扩展了智能查询处理功能集,通过将查询反馈功能引入主产品,使 SQL Server 能够根据之前的低效情况调整执行计划,从而扩展其适应能力。这些功能此前已经在 Azure SQL 数据库中作为预览版本提供,而内存授权反馈在过去三个版本中也逐步引入到核心产品中。
这些查询反馈功能利用查询存储(Query Store)来允许比较不同的执行计划及其相关的性能。因此,要按照本节中的示例操作,需要为 MarketingArchive 数据库启用查询存储。可以使用列表 10.8 中的命令来实现此操作。
提示: 从 SQL Server 2022 开始,查询存储默认已启用。在 Azure SQL 数据库和 Azure 托管实例中,它也默认启用。
ALTER DATABASE MarketingArchive
SET QUERY_STORE = ON (OPERATION_MODE = READ_WRITE) ;
提示: 对 Query Store 的全面讨论超出了本书的范围,但微软在 https://mng.bz/YVmA 提供了一个演练。
想象一下,我们的实例在某些时期查询开始变慢。我们通过检查等待统计信息进行调查,发现 CX_PACKET 和 SOS_SCHEDULER_YEILD 等待类型的值非常高。我们还注意到,每当执行大型报告查询时,问题就会发生。我们查看查询计划,发现该查询以最大并行度(MAXDOP)为 16 执行。
提示: 在 SQL Server 2016 服务包 2 和 SQL Server 2017 累积更新 4 之前,CX_PACKET 提供了不一致的结果。自从这个错误被修复后,它变得非常有用。
所有症状都表明问题是由大型报表查询引起的,该查询以一种实际上对自身执行时间和同时运行的其他查询都有害的并行度运行。
我们已经将实例范围的 MAXDOP 设置更改为 16,以利于其他一些查询,因此我们决定在有问题的查询中添加 MAXDOP 8 查询提示。然而,这是一个错误。为什么?因为我们正在运行 SQL Server 2022,这意味着我们可以启用 DOP 反馈,让 SQL Server 根据执行统计持续评估并更改查询计划中使用的 DOP。为什么数据库管理员会犯这个错误?有两个原因:(1)DOP 反馈是三种查询反馈功能中唯一默认未启用的;(2)在数据库管理员繁忙的工作生活中,当 SQL Server 发布新功能时,并不总是有可能及时跟进所有新功能。这是一个很好的例子,说明了解和实施新功能的重要性,因为它可以节省数据库管理员大量时间,让他们有更多精力去处理更高价值的任务。
SQL Server 2022 提供以下查询反馈选项,这些选项是智能查询处理套件的一部分。
- DOP 反馈
- 基数估计反馈
- 内存授予反馈
我们已经讨论过 DOP 反馈。它允许 SQL Server 根据历史执行情况优化查询的 DOP。
基数估算(CE)帮助 SQL Server 根据对查询执行中每个步骤将处理多少行的估计来选择最合适的执行计划。基于列和索引统计信息并通过复杂算法得出的这些估计,有时可能不准确。这是因为不可能开发一种算法来考虑每一个用户的具体需求和使用模式。估计不准确可能导致次优的查询计划,最终导致查询性能不佳。CE 反馈可以帮助 SQL Server 识别不准确的估计并做出更好的选择。
内存授予反馈根据历史信息调整查询的内存授予。这可以帮助避免内存授予过小,从而导致数据被转储到磁盘。它还可以帮助避免内存授予过高,从而导致并行化效果不佳。
与 DOP 反馈和 CE 反馈不同,这两者都是 SQL Server 2022 中的新功能,内存授予反馈是在 SQL Server 最近三次主要版本中分阶段实现的。批处理模式的内存授予反馈在 SQL Server 2017 中实现,行模式的内存授予反馈在 SQL Server 2019 中实现。SQL Server 2022 实现了百分位和持久模式。这将实现引入到查询存储中,以便用于决策的统计信息在实例重启时不会丢失。
如果数据库启用了查询存储,则默认会启用内存授权反馈和CE反馈,前提是数据库的兼容性级别对于内存授权反馈为140或更高,对于CE反馈为160或更高。不过,DOP反馈默认是关闭的。可以使用以下清单中的命令将其开启。
ALTER DATABASE SCOPED CONFIGURATION
SET DOP_FEEDBACK = ON ;
下面列表中的查询可用于确定所涉数据库启用了哪些查询反馈功能。
SELECT
name
, CASE
WHEN value = 1 THEN ‘Enabled’
ELSE ‘Disabled’
END as Enabled
FROM sys.database_scoped_configurations
WHERE name LIKE ‘%feedback%’ ;
在兼容级别为160或更高的数据库中启用DOP反馈是一个好的做法。这消除了DBA需要手动评估和优化查询的MAXDOP设置的需求。
错误60# 不对大表进行分区
SQL Server 通常受 I/O 限制。这意味着磁盘子系统是影响查询性能的瓶颈。对于对非常大的表运行报表类型查询的超大数据库,这一点尤其正确。
让我们考虑一下 MarketingArchive 数据库。假设我们的实例在 IOPS 上有压力,并且清单 10.11 中的查询经常被运行。脚本中的第一个命令会为会话开启 I/O 统计信息。
SET STATISTICS IO ON ;
GO
SELECT *
FROM dbo.ImpressionsArchive
WHERE EventTime >= ‘20210101’ AND EventTime <= ‘20211231’ ;
如果我们查看图 10.6 所示的查询计划,我们会注意到正在执行聚集索引扫描。这意味着表中的每一行都被读取。
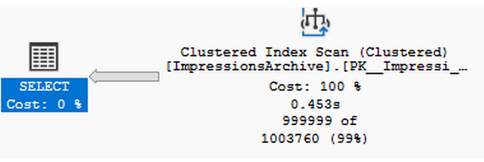
让我们来看一下此查询的 I/O 统计信息。由于会话已启用 I/O 统计信息,它们将显示在“消息”选项卡中:
Table ‘ImpressionsArchive’. Scan count 1, logical reads 46979,
physical reads 1, page server reads 0, read-ahead reads 46981,
page server read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob page server reads 0, lob read-ahead reads 0,
lob page server read-ahead reads 0.
缓冲区缓存是冷的,所以 SQL Server 对所有需要的页面执行了物理读取(1 次物理读取和 46,981 次预读)。预读将剩余所需页面放入缓冲区缓存,这就是统计数据显示 46,979 次逻辑读取的原因。
清除缓存
出于测试目的,有时清除缓冲区缓存是有帮助的,这样页面就需要从磁盘读取。如果你不这样做,第二次运行查询时页面已经在缓存中,这意味着测试结果无效。
您可以通过运行以下命令来清除缓冲缓存中的页面:
CHECKPOINT
DBCC DROPCLEANBUFFERS
第一个命令会将已修改的脏页刷新到磁盘。第二个命令会将未修改的干净页从缓存中移除。
如果你计划重复运行测试,那么在脚本开始时运行这些命令是一种良好的做法。然而,请记住,你应当仅在开发或测试服务器上执行此操作。在生产服务器上运行这些命令可能会影响性能。
我经常看到数据库管理员犯的一个错误是调查到这一步,检查缺失的索引,然后停止,要么说“抱歉,就是这样!”,要么联系存储团队看看他们是否能从 SAN 中挤出更多性能。他们应该做的是调查一个被严重低估的功能,叫做表分区。
表分区是 SQL Server 的一个长期存在的功能,它根据分区键将表拆分为多个较小的表。对于开发人员来说,这种拆分是完全无缝的,因为表仍然显示为单个表,并且不需要更改任何代码。
将一个有报告式查询的大表进行分区有两个很大的优势。第一个优势是可以将每个分区放在不同的文件组上。如果这些文件组中的文件存储在不同的磁盘上,分区可以并行读取。
在我看来,第二个更重要的优点是能够消除分区。换句话说,SQL Server 可以仅从所需的分区读取数据,而忽略不包含相关数据的分区。这可以显著减少读取操作,减轻 I/O 子系统的压力。它还可以直接提高查询的性能,因为读取的数据减少了。
那么,为什么数据库管理员(DBA)不利用这个功能呢?我遇到过三个原因。第一个原因是他们根本不知道这个功能。我总觉得这很令人惊讶,因为该功能是在 SQL Server 2005 中引入的——几乎 20 年前了!第二个原因是政治上的争论。我曾见过这样的情况,DBA 团队坚持认为编写分区对象是开发人员的责任,因为他们不了解应用程序。同时,开发人员拒绝实现该功能,因为他们不是 DBA,不了解分区。这可以通过协作轻松解决。如果两个团队能够合作,那么实施将会很简单。
最后一个原因是对该技术的工作原理或如何实施缺乏了解。让我们在本节的剩余部分讨论这个原因。
要创建分区表或对现有表进行分区,必须创建分区函数和分区方案。为了理解这些概念,我喜欢使用一个有多个田地的农场的类比。田地之间有围栏,这样可以在每个田地种植不同的作物。
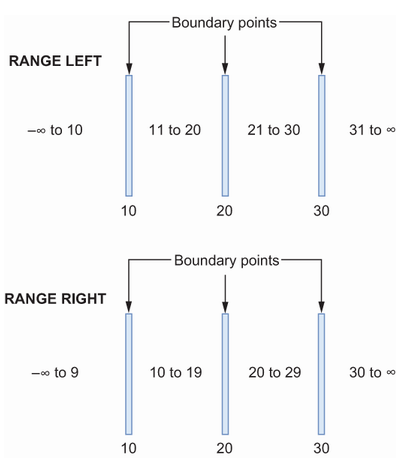
使用这个类比,分区函数就是围栏。它定义了边界点:一个场结束和下一个场开始的地方。当我们创建分区函数时,我们指定边界点的数据类型、具体的边界点值,以及范围是左闭还是右闭。
左右范围用于确定落在边界点上的值是放置在边界点的左侧还是右侧。这个区别在图10.7中有所说明。在这个例子中,一个分区函数为整数值10、20和30创建了边界点。
分区方案定义了每个分区放置在哪个文件组上。我们可以选择为每个分区指定不同的(预先创建的)文件组,或者指定 ALL 关键字,以表示我们希望将所有分区存储在同一个文件组上。
最后,当我们创建一个表时,我们用 ON <PARTITION SCHEME>(<PARTITIONING KEY>) 子句替换 ON <FILEGROUP> 子句。这种架构意味着可以在单个分区方案上创建多个分区,并且可以在单个分区函数上创建多个分区方案。
清单 10.12 中的脚本创建了一个名为 ImpressionDatesPF 的分区函数,它使用 range right 和 DATETIME 数据类型。它在 2020 年、2021 年、2022 年和 2023 年的 1 月 1 日创建边界点。然后,它创建了一个名为 ImpressionDatesPS 的分区方案,将所有分区映射到 PRIMARY 文件组。接下来,脚本在 ImpressionDatesPS 分区方案上创建一个新表,名为 ImpressionArchivePartitioned,使用 EventTime 列作为主键,然后在 ImpressionID 和 EventTime 列上创建 PRIMARY KEY。需要理解的是,在处理分区表时,分区键必须是表中任何唯一键的子集。我们创建新表而不是对现有表进行分区有两个原因。首先,它允许对这两种方法进行比较;其次,我们将在后续示例中使用 ImpressionArchive 表。
CREATE PARTITION FUNCTION ImpressionDatesPF (DATETIME)
AS RANGE RIGHT FOR VALUES (‘20200101’, ‘20210101’, ‘20220101’, ‘20230101’);
GO
CREATE PARTITION SCHEME ImpressionDatesPS
AS PARTITION ImpressionDatesPF
ALL TO ([PRIMARY]) ;
GO
CREATE TABLE dbo.ImpressionsArchivePartitioned(
ImpressionID BIGINT NOT NULL IDENTITY(1,1),
ImpressionUID UNIQUEIDENTIFIER NOT NULL,
ReferralURL VARCHAR(512) NOT NULL,
CookieID UNIQUEIDENTIFIER NOT NULL,
CampaignID BIGINT NOT NULL,
RenderingID BIGINT NOT NULL,
CountryCode TINYINT NULL,
StateID TINYINT NULL,
BrowserVersion BIGINT NOT NULL,
OperatingSystemID BIGINT NOT NULL,
BidPrice MONEY NOT NULL,
CostPerMille MONEY NOT NULL,
EventTime DATETIME NOT NULL,
) ON ImpressionDatesPS(EventTime) ;
GO
ALTER TABLE dbo.ImpressionsArchivePartitioned ADD CONSTRAINT
PK_ImpressionsArchivePartitioned PRIMARY KEY (ImpressionID, EventTime) ;
GO
INSERT INTO dbo.ImpressionsArchivePartitioned (
ImpressionUID,
ReferralURL,
CookieID,
CampaignID,
RenderingID,
CountryCode,
StateID,
BrowserVersion,
OperatingSystemID,
BidPrice,
CostPerMille,
EventTime
)
SELECT
ImpressionUID
, ReferralURL
, CookieID
, CampaignID
, RenderingID
, CountryCode
, StateID
, BrowserVersion
, OperatingSystemID
, BidPrice
, CostPerMille
, EventTime
FROM dbo.ImpressionsArchive ;
现在让我们看看通过运行清单10.13中的查询,这对I/O需求造成了什么影响。
SELECT *
FROM dbo.ImpressionsArchivePartitioned
WHERE EventTime >= ‘20210101’ AND EventTime <= ‘20211231’ ;
该查询的 I/O 统计信息是
Table ‘ImpressionsArchivePartitioned’. Scan count 1, logical reads 15732,
physical reads 2, page server reads 0, read-ahead reads 15736,
page server read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob page server reads 0, lob read-ahead reads 0,
lob page server read-ahead reads 0.
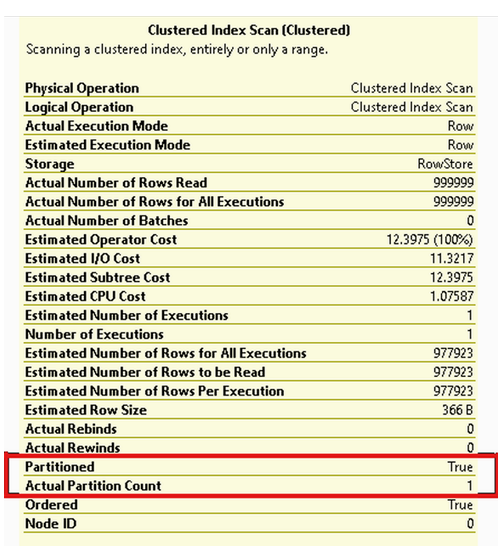
尽管查询返回的行完全相同,但它从磁盘读取的页面不是46,982页,而只是15,738页。如果我们检查图10.8所示的查询计划,原因就很明显了。尽管仍然执行了聚集索引扫描,但除了一个分区之外,其他所有分区都已被排除,这意味着只需要读取三分之一的数据。
如果你有非常大的表,并且其典型的使用模式是用于报表查询,你应该考虑对表进行分区。这种方法允许在不需要分区时将其排除,从而可以显著减轻I/O子系统的压力并提高查询性能。
错误61# 不了解分区消除的限制
在前一节中,我们讨论了当我们拥有非常大的表时,分区功能有多么有用。其好处来自分区消除;SQL Server 可以选择仅从所需的分区读取数据。然而,由于每个分区都作为单独的 B 树存储,如果我们的查询无法利用分区消除,那么查询实际上可能比对非分区表的查询更慢。因此,在没有考虑将使用该分区的查询的情况下实施分区是一个错误。
我无法过分强调分区键对于实现分区消除的重要性。分区消除无法生效的最常见原因之一是开发人员编写的查询未使用分区键。例如,如果我们在分区键和另一列上进行筛选,那么分区消除将有效。然而,如果我们在分区键或另一列上进行筛选,则需要读取所有分区。这在清单10.14中有所说明。脚本中的第一个查询只会访问单个分区。然而,第二个查询使用了或逻辑,需要读取表中的所有分区。
SELECT *
FROM dbo.ImpressionsArchivePartitioned
WHERE CampaignID = 44538
AND EventTime >= ‘20210101’ AND EventTime <= ‘20211231’ ;
SELECT *
FROM dbo.ImpressionsArchivePartitioned
WHERE CampaignID = 44538
OR EventTime >= ‘20210101’ AND EventTime <= ‘20211231’ ;
另一个常见的问题原因是 SQL Server 需要执行转换的情况。例如,我们的 ImpressionsArchivePartitioned 表在 EventTime 列中使用 DATETIME 数据类型。在到目前为止的示例中,SQL Server 能够将我们的字面值与该列进行比较,即使该字面值被格式化为 DATE,因为在优先级顺序中 DATETIME 高于 DATE。然而,如果我们显式地将值类型指定为 DATE,那么 SQL Server 就需要进行转换,这将导致分区消除无法工作。例如,下面列表中的第一个查询会读取表的所有分区,而第二个查询则能够消除除一个分区以外的所有分区。
DECLARE @StartDate DATE ;
SET @StartDate = ‘20210101’ ;
DECLARE @EndDate DATE ;
SET @Enddate = ‘20211231’ ;
SELECT *
FROM dbo.ImpressionsArchivePartitioned
WHERE EventTime >= @StartDate AND EventTime <= @EndDate ;
GO
DECLARE @StartDate DATETIME ;
SET @StartDate = ‘20210101’ ;
DECLARE @EndDate DATETIME ;
SET @Enddate = ‘20211231’ ;
SELECT *
FROM dbo.ImpressionsArchivePartitioned
WHERE EventTime >= @StartDate AND EventTime <= @EndDate ;
问题的最后一个常见原因是简单的参数化。如果 SQL Server 认为它可以重用执行计划,它将通过对筛选条件的值进行参数化来促进重用。这将阻止分区消除的正常工作。
我们可以通过两种不同的方式解决这个问题。第一种解决方法是指定 RECOMPILE 选项。这将防止简单参数化,因为计划甚至不会被缓存。这显然有一个缺点,即每次查询运行时都必须重新编译计划。
第二种解决方法是在查询中添加一个静态的不等运算符,例如 1 <> 2。这将防止简单的参数化,但执行计划仍会被缓存,因此可以实现一定程度的重用。
清单 10.16 有三个查询。第一个查询将读取表的所有分区。第二个和第三个查询将只读取单个分区。
SELECT COUNT(*)
FROM dbo.ImpressionsArchivePartitioned
WHERE EventTime >= ‘20210101’ AND EventTime <= ‘20211231’ ;
GO
SELECT COUNT(*)
FROM dbo.ImpressionsArchivePartitioned
WHERE EventTime >= ‘20210101’ AND EventTime <= ‘20211231’
OPTION(RECOMPILE) ;
GO
SELECT COUNT(*)
FROM dbo.ImpressionsArchivePartitioned
WHERE EventTime >= ‘20210101’ AND EventTime <= ‘20211231’
AND 1<>2 ;
GO
这两种变通方法都将导致动态分区消除。这意味着 SQL Server 会在执行时而不是编译时决定消除分区。图 10.9 展示了清单 10.16 中第三个查询的查询计划中的查找谓词。您会注意到使用了一个值为 3 的标量操作符来确定需要访问的分区。
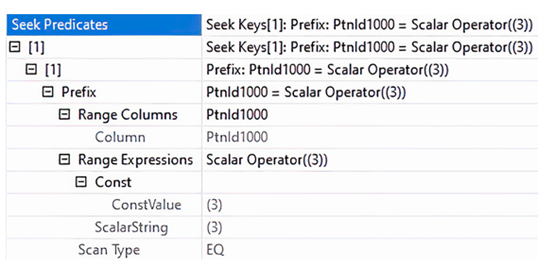
对大型表进行分区可以带来非常有价值的性能提升。然而,贸然进行分区而不开发确保分区消除发生的代码是一种错误。重要的是,我们要理解分区消除的限制,如果分区消除未发生,性能可能会下降。
通过避免简单的参数化、避免 SQL Server 需要转换值,以及确保开发人员编写使用分区键进行过滤或连接的代码,我们可以解决许多分区消除的问题。然而,如果代码与分区消除不兼容,那么我们应该避免使用分区,因为它实际上可能对性能产生负面影响。
错误62# 不压缩大表
在上一节中,我们讨论了使用分区作为缓解 I/O 子系统压力以提高查询性能的一种方法。另一种方法是考虑压缩。当大多数数据库管理员想到压缩时,他们会认为这是以牺牲性能为代价来减少数据大小,但这是一个误解,并导致 SQL Server 中压缩的利用不足,而压缩可以在某些工作负载下提高查询性能。
如果 SQL Server 的性能受限于 I/O,而处理器有空闲容量,那么行压缩和页压缩可以减少 SQL Server 需要从磁盘读取的页面数量,从而缓解 I/O 子系统的压力,但会消耗额外的处理器周期。
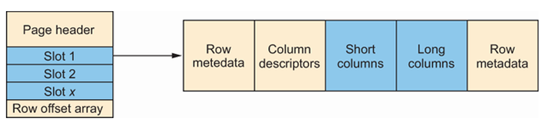
要理解压缩的工作原理,了解未压缩的数据页如何在行内组织数据是很有帮助的。这在图10.10中有所说明。图的左侧显示了高层次的页结构,其中一个槽是物理行的容器。图的右侧显示了槽内数据的结构方式。
让我们来思考一下 ImpressionArchive 表。我们从上一节中已经知道,要读取该表中的所有行,我们必须读取 46,982 页。但如果我们实施行压缩会怎样呢?让我们使用清单 10.17 中的命令来实现行压缩。
ALTER TABLE ImpressionsArchive
REBUILD WITH (DATA_COMPRESSION = ROW) ;
压缩后的表现在使用 33,687 页来存储数据——大约减少了 28%。我们可以通过执行没有 WHERE 子句的查询并查看 I/O 统计信息,或者通过执行清单 10.18 中的查询(从元数据中获取页面计数)来确定表使用的页面数量。通过 index_id = 1 进行过滤可以确保我们只统计聚集索引的页面。
SELECT
in_row_used_page_count
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID(‘ImpressionsArchive’)
AND index_id = 1 ;
行压缩通过实现 VARDECIMAL 系统来工作。这意味着不仅仅是 VARCHAR、NVARCHAR 和 VARBINARY 是可变长度的数据类型,十进制值也变为可变长度。例如,在 BIGINT 列中,值 10 只会占用 1 字节空间,因为它会存储为 TINYINT,而值 50,000 只会占用 4 字节,因为它会存储为 INT。NULL 值则不会占用任何空间。行压缩还会从定长字符列中去除填充的空格,并在可能的情况下将 Unicode 值压缩为每个字符 1 字节。
考虑到这一点,让我们来看看在实现了行压缩的数据页上数据是如何存储的。将图10.11所示的这种结构与未压缩页面的结构进行比较。
如果我们使用页面压缩会怎样?下面清单中的命令为 ImpressionArchive 表实现了页面压缩。
ALTER TABLE ImpressionsArchive
REBUILD WITH (DATA_COMPRESSION = PAGE) ;
当您实现页面压缩时,之前描述的行压缩技术会被实现。随后会实现前缀压缩和字典压缩。
前缀压缩查看存储在同一页的同一列的多行中的值,并尝试为这些行识别一个共同的前缀。它选择包含完整前缀的最长值作为锚点。该列中的所有其他值都作为锚点的差异存储。
在实现前缀压缩之后,字典压缩是页面压缩过程的最后一步。这一步会检查页面中存储的所有值,并寻找重复值。真正巧妙的是,这些值是通过它们的二进制表示来评估的,这使得该过程与数据类型无关,并提高了压缩率。匹配的值会存储在页面顶部的字典中,而行只存储指向字典中该值位置的指针。
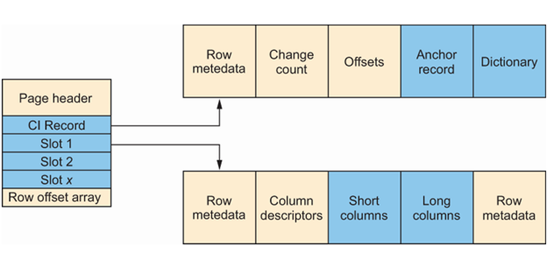
图10.12展示了实施页面压缩的数据页结构。您会注意到,槽结构与行压缩时相同。然而,您还会注意到,增加了一个CI记录。它在页面头之后立即插入,作为前缀压缩的锚点以及字典压缩的字典。更改计数用于跟踪页面被更新的次数,因为这可能影响CI记录的有效性。SQL Server使用此信息来决定页面是否需要重建。
页面压缩对我们的 ImpressionArchive 表的大小有什么影响?没有!该表仍然占用 33,687 页。这是为什么呢?嗯,在我们的情况下,该表是使用随机值构建的,比如全局唯一标识符和随机生成的字符串,这意味着共同点非常少,因此无法进行压缩。
我们可以使用存储过程 sp_estimate_data_compression_savings 来估算在实施更改之前不同压缩级别下表的大小。在我们的案例中,这本可以帮助我们决定使用行压缩而不是页压缩。这本会是一个好的选择,因为页压缩并没有比行压缩进一步减小表的大小,尽管它在解压缩页时比行压缩需要更多的处理器周期。
下列清单显示了如何使用存储过程 sp_estimate_data_compression_savings 来估算如果我们移除所有压缩时表的大小,与当前已实现页面压缩的表大小进行比较。
EXEC sp_estimate_data_compression_savings
@schema_name = ‘dbo’,
@object_name = ‘ImpressionsArchive’,
@index_id = 1,
@partition_number = NULL,
@data_compression = ‘none’ ;
当我们在 I/O 受限的 SQL Server 实例上有大表时,我们应评估数据压缩作为一种性能优化技术。为了使数据压缩可行,实例必须是 I/O 受限的,并且必须有多余的处理器容量。我们应在实施压缩之前评估行压缩和页压缩的影响。这是因为每种技术根据表中数据的性质会有不同的压缩率。页压缩通常能实现更好的压缩率,但代价是增加 CPU 的解压压力。
错误63# 使用未提交读取
在第5章中,我们讨论了将 NOLOCK 查询提示作为性能优化的做法是一个错误,因为缺少锁可能导致返回非确定性结果,但许多 SQL Server 专业人员在处理事务级别的锁定时也会犯错误。
未提交读事务隔离级别的工作方式类似于 NOLOCK,但作用于事务级别。它在读操作时不获取任何锁。这避免了锁争用,但可能导致脏读,即读取了从未提交到数据库的数据。
这意味着,只有在针对存储在只读文件组中的表时,Read Uncommitted 才是合适的选项,也就是说,数据不能写入这些表。不幸的是,在处理接受更新的表时,看到 SQL Server 专业人员将此隔离级别作为性能优化手段并不少见。
为了理解脏读现象,我们来考虑以下示例。一个数据管理员正忙于解决 MarketingArchive 数据库中的一些数据问题。与此同时,一个用户正在运行报告。
提示: 要跟随此示例操作,您应该打开两个查询窗口。第一个查询窗口应用于执行清单 10.21 和 10.23 中的查询。第二个查询窗口应用于执行清单 10.22 中的脚本。
以下清单中的查询模拟数据管理员在 ImpressionsArchive 表中更新 ImpressionID 为 100 的展示记录的 BidPrice。
BEGIN TRANSACTION
UPDATE dbo.ImpressionsArchive
SET BidPrice = 1.812
WHERE ImpressionID = 100 ;
下列清单中的查询模拟数据库用户运行报表,该报表返回与一个活动相关的所有出价价格(BidPrice)值的总和。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
BEGIN TRANSACTION
SELECT SUM(BidPrice)
FROM dbo.ImpressionsArchive
WHERE CampaignID = (
SELECT
CampaignID
FROM dbo.ImpressionsArchive
WHERE ImpressionID = 100
) ;
COMMIT
下面列表中的命令回滚数据管理员的事务,因为他们已经意识到自己犯了一个错误。
ROLLBACK ;
不幸的是,这一系列事件意味着报告用户返回的查询是“错误的”,因为它基于从未提交到数据库的数据,如果再次运行该查询,结果将会不同。
在正常情况下,不要将“读取未提交(Read Uncommitted)”事务隔离级别作为性能优化手段。仅当从存储在只读文件组中的表中读取数据时,或者在极少数数据准确性无关紧要的情况下,使用此隔离级别才是合适的。
错误64# 使用不必要的高隔离级别
已提交读(Read Committed)事务隔离级别是 SQL Server 的默认隔离级别,并能防止脏读。然而,它会使用户面临不可重复读的风险,即事务对同一行进行两次读取时每次得到的值可能不同。它还会使用户面临幻读的风险,即事务对一组行进行两次读取时每次收到的行数可能不同。
我曾见过一些情况,数据库专业人员认为他们的数据非常重要,因此他们将可重复读隔离级别用作默认事务,该级别可以防止脏读和不可重复读;或者使用可串行化隔离级别,该级别可以防止所有一致性问题,包括幻读。
在某些情况下,例如在进行精算计算时,使用可重复读(Repeatable Read)和可串行化(Serializable)事务隔离级别是完全有效且必要的,但设置这些隔离级别通常是过度的。在许多常规需求的情况下,配置这些更高的隔离级别是一个错误。在绝大多数情况下,保持默认的读已提交(Read Committed)配置是正确的做法。
为了帮助在特定用例中做出关于使用正确隔离级别的明智选择,让我们来探讨不可重复读和幻读的后果。要跟随接下来的两个示例,您将需要使用两个查询窗口。每个示例都会指出应在哪个查询窗口中运行查询。
让我们首先探讨不可重复读。想象一下,再次数据管理员正在更新行以修复 ImpressionsArchive 表中的数据错误。这一次,我们的报表用户将使用默认的已提交读(Read Committed)事务隔离级别。报表用户的事务从以下清单中的代码开始。
BEGIN TRANSACTION
SELECT SUM(BidPrice)
FROM dbo.ImpressionsArchive
WHERE OperatingSystemID = (
SELECT OperatingSystemID
FROM dbo.ImpressionsArchive
WHERE ImpressionID = 100
) ;
清单10.25中的脚本模拟了数据管理员修正ImpressionID为100的曝光的BidPrice。这次,数据管理员立即提交了更改。
BEGIN TRANSACTION
UPDATE dbo.ImpressionsArchive
SET BidPrice = 1.5
WHERE ImpressionID = 100 ;
COMMIT
最后,下面列出的脚本展示了报告用户交易的结束。
SELECT SUM(BidPrice)
FROM dbo.ImpressionsArchive
WHERE CountryCode = (
SELECT CountryCode
FROM dbo.ImpressionsArchive
WHERE ImpressionID = 100
) ;
COMMIT
在这一系列事件中,报告用户在两个不同的查询中两次读取了 ImpressionID 为 100 的展示的出价(BidPrice)值。第二次读取 BidPrice 时,其值与第一次读取时不同。两个值都不是“错误”的——它们在从表中读取时都是正确的。然而,如果用户尝试调和这两个查询中的值,很可能会感到困惑,并且结果肯定是不一致的。
在许多情况下,这种类型的异常并不重要。例如,如果我们正在进行监管财务计算,那么我们可能需要将隔离级别设置为可重复读。然而,如果该异常是可以接受的,那么我们应该保持默认的已提交读隔离级别。
现在让我们来探讨幻读。我们的数据管理员回来了,但这一次,错误的数据正在被删除。下面列表中的脚本开始了我们报表用户的事务。
BEGIN TRANSACTION
SELECT COUNT(*)
FROM dbo.ImpressionsArchive
WHERE OperatingSystemID = (
SELECT OperatingSystemID
FROM dbo.ImpressionsArchive
WHERE ImpressionID = 100
) ;
接下来,下面列表中的脚本模拟数据管理员从表中删除行。
BEGIN TRANSACTION
DELETE
FROM dbo.ImpressionsArchive
WHERE ImpressionID IN (
SELECT TOP 3 ImpressionID
FROM dbo.ImpressionsArchive
WHERE OperatingSystemID = (
SELECT OperatingSystemID
FROM dbo.ImpressionsArchive
WHERE ImpressionID = 100
)
AND ImpressionID <> 100
) ;
COMMIT
最后,下面的列表中的脚本显示了报告用户交易的结束。
SELECT COUNT(DISTINCT ImpressionID)
FROM dbo.ImpressionsArchive
WHERE OperatingSystemID = (
SELECT OperatingSystemID
FROM dbo.ImpressionsArchive
WHERE ImpressionID = 100
) ;
COMMIT
在这种情况下,当报告用户运行第二个查询时,它返回的行比第一个查询少三行。这被称为幻读,但如果表中插入了行,也会被称为幻读,这意味着第二个查询返回了更多的行。
幻读在许多情况下并不被认为是重大问题。如果我们知道存在像精算计算这样的场景,其中幻读会成为问题,那么我们应该考虑使用可串行化事务隔离级别。否则,我们应使用较弱的隔离级别,理想情况下为已提交读取(Read Committed)。
更高的隔离级别可以防止更多的数据异常,但可能导致由于锁争用而引起的性能问题。它们甚至可能导致死锁,当两个事务互相等待对方完成而无法继续时就会发生死锁。死锁会导致 SQL Server 认为成本最低的查询被回滚。因此,只有在有正当需求时,我们才应使用更高的隔离级别。
错误65# 不考虑乐观隔离级别
SQL Server 支持两种类型的事务隔离级别:悲观和乐观。悲观隔离级别使用锁来防止其他事务更新数据。乐观隔离级别在 TempDB 中存储行的旧版本。这在避免数据异常的同时,防止读写操作相互阻塞带来的性能问题。
在前两个部分中,我们讨论了悲观事务隔离级别。在本节中,我们将探讨 SQL Server 支持的两种乐观隔离级别。这些隔离级别分别称为已提交读快照(Read Committed Snapshot)和快照(Snapshot),分别相当于已提交读(Read Committed)和可串行化(Serializable),并且它们可以防止数据异常。
这些隔离级别的工作方式是将旧行版本存储在 TempDB 中,直到最旧的未提交事务中的最旧行版本为止,这意味着事务可以引用行的正确版本,而无需使用与悲观隔离级别相关的锁定和阻塞。
不幸的是,这些有用的隔离级别被大多数数据库管理员忽视了。我认为其主要原因是害怕出错。这可以理解,因为乐观并发绝不是魔法药丸。
没有万能方法
虽然本节提倡考虑乐观并发,但重要的是要注意,它并不是万能的。像在 SQL Server 中的大多数事情一样,这存在权衡。
行版本存储在称为 Version Store 的 TempDB 区域中。对于繁忙的生产数据库系统,这可能意味着与乐观隔离级别相关的大量额外 I/O。鉴于本章有两节专门介绍减少 I/O 量的方法,你可以看到这可能会带来潜在的挑战。我们还需要考虑将使用的额外磁盘空间量。
在考虑像乐观并发这样的特性时,我们需要根据具体情况逐案评估。例如,如果我们的 TempDB 存储在本地非易失性内存快速驱动器(NVMe)上,并且有大量空闲空间,那么切换到乐观并发可能是一个非常好的主意。另一方面,如果 TempDB 存储在一个性能低下的存储区域网络(SAN)上,并且我们正经历 I/O 瓶颈,那么实施此功能可能弊大于利。
本节中的错误是在特定场景下未考虑乐观并发。在合适的情况下,读取已提交快照(Read Committed Snapshot)和快照隔离(Snapshot isolation)可以成为我们在应对棘手性能问题时非常有用的工具。
如果我们在评估一个由于锁定和阻塞而导致性能问题的情况,但强隔离性是必要的,我们当然应该评估实施已提交读快照(Read Committed Snapshot)和/或快照隔离(Snapshot isolation)的潜力。然而,我们确实需要注意 I/O 要求,并避免在 I/O 受限的环境中实施它。
我们可以通过使用下列清单中的命令来启用已提交读取快照隔离。
ALTER DATABASE MarketingArchive
SET READ_COMMITTED_SNAPSHOT ON WITH NO_WAIT ;
一旦启用已提交读快照,就无法使用悲观的已提交读隔离级别,并且已提交读快照将成为所有事务的默认隔离级别。
下面清单中的脚本演示了如何为数据库启用快照隔离。
ALTER DATABASE MarketingArchive
SET ALLOW_SNAPSHOT_ISOLATION ON ;
因为已提交读快照现在是默认的隔离级别,我们可以通过启动任何事务然后查看系统元数据来检查版本存储中的行。下面列表中的脚本启动一个事务并更新一行。
BEGIN TRANSACTION
UPDATE dbo.ImpressionsArchive
SET BidPrice = BidPrice + 0.1
WHERE ImpressionID = 100 ;
UPDATE dbo.ImpressionsArchive
SET CostPerMille = CostPerMille + 0.1
WHERE ImpressionID = 100 ;
我们现在可以通过执行下列清单中的查询来查看版本存储。
SELECT *
FROM sys.dm_tran_version_store ;
COMMIT
您会注意到,行的原始版本是以二进制值存储的,字节长度存储在一个额外的列中。
每种情况都是不同的,如果你处于IO压力之下,那么乐观并发可能不是正确的解决方案。也就是说,如果你因为悲观并发而遇到性能问题而不考虑它,那将是一个错误。对于DBA来说,在合适的情况下,Read Committed Snapshot和Snapshot隔离级别可能是有用的工具。
错误66# 对问题投入更多硬件
整整一章都致力于优化 SQL Server 性能,但我一次又一次看到的一个错误,通常是由管理支持合作伙伴犯的,是未能深入挖掘性能问题,而是试图增加更多硬件来解决问题。
这种方法从来都不是一个好主意。其主要问题在于,如果你遇到性能问题,增加硬件规模不太可能解决问题;即使它真的解决了问题,效果也可能是短暂的,你还是需要再次升级。
让我们来看看下面列出的一个写得非常糟糕的查询,它只是更新 MarketingArchive 表中所有行的 BidPrice 列,但却使用了游标。
注意: 这个脚本可能需要很长时间才能运行。
DECLARE @ImpressionID BIGINT
DECLARE Impressions CURSOR FAST_FORWARD FOR
SELECT ImpressionID
FROM dbo.ImpressionsArchive ;
OPEN Impressions ;
FETCH NEXT FROM Impressions INTO @ImpressionID
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE dbo.ImpressionsArchive
SET BidPrice = BidPrice + 0.1
WHERE ImpressionID = @ImpressionID ;
FETCH NEXT FROM Impressions INTO @ImpressionID ;
END
CLOSE Impressions ;
DEALLOCATE Impressions ;
在我的测试设备上,这个查询花了整整10分15秒才能运行完。图10.13显示了查询运行时机器的资源使用情况。
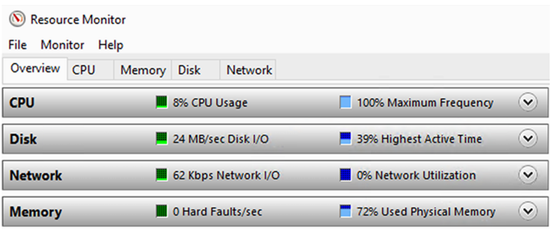
虽然这可能是一个夸张的情景,但我经常与初级数据库管理员交谈,他们会争辩说,一个性能问题是由处理器使用率引起的,因为使用率曾经猛增到100%,即使现在已经降到8%。他们并不打算调查问题的原因,而只是想增加更多的处理器来应对这种情况。
现在你可能已经意识到,无论你投入多少硬件来解决这个问题都无济于事;解决的唯一方法是重写查询,如下面的清单所示,在我的测试设备上运行只需3秒钟。
UPDATE dbo.MarketingArchive
SET BidPrice = BidPrice + 0.1 ;
即使这种诊断方法在虚拟机时代从未有用,它现在在云时代也成为了一种成本考虑。通过增加云虚拟机的大小或购买更快的存储来提高性能问题,只会无谓地花费更多的钱。
当然,有些时候工作负载会超过服务器的可用容量,需要进行升级,但希望我们在容量规划期间已经注意到并进行了计划,这在第9章中有讨论。
我们应该始终尝试解决性能问题,而不是默认进行硬件升级。升级硬件并不一定能解决问题,或者可能只是暂时缓解症状。相反,我们应该努力找到问题的根本原因。我们可以使用本章讨论的性能优化方法,确保遵循第5章讨论的编码最佳实践,或使用 SQL Server 提供的各种功能和诊断工具来解决问题。
总结:
- 跟踪标志用于开关 SQL Server 功能。
- 跟踪标志 T1117 和 T1118 已被弃用,不再对 SQL Server 实例产生任何影响。应改用更细粒度的替代方案,例如 AUTOGROW_ALL_FILES 和 UNIFORM_PAGE_ALLOCATION。
- 实例文件初始化应在绝大多数情况下使用。只有在最安全的环境中才应避免使用。
- 锁定内存中的页面应该在许多情况下使用。在私有云中,有时应该禁用它,但公共云提供商建议使用它。
- 始终为操作系统和服务器上运行的其他应用程序保留足够的内存。如果使用了“锁定内存中的页面”,这一点尤其重要。
- 使用最大服务器内存设置来配置可以分配给 SQL Server 缓冲池的最大 RAM 数量。
- 总是尽量与优化器配合,而不是与之对抗。在极少数需要使用查询提示的情况下,尽量给优化器留下多种选项。
- 记得利用 DOP 查询反馈。
- DOP反馈默认是禁用的,不同于其他查询反馈机制。
- 考虑对大型表进行分区以提高性能并减少对 I/O 子系统的负载。
- 分区表允许进行分区消除,这意味着如果分区不存储相关数据,则不会读取这些分区。
- 考虑使用数据压缩作为大型表的性能提升手段。
- 数据压缩最适合于I/O受限且有多余处理器容量的工作负载。
- 实现的压缩率将取决于表中存储的数据。在实施行压缩或页压缩选项之前,使用 sp_estimate_data_compression_savings 存储过程评估其影响。
- 除非您使用存储在只读文件组中的表,否则应避免使用“读取未提交”事务隔离级别。
- 读取未提交(Read Uncommitted)隔离级别可能会导致脏读,就像使用 NOLOCK 查询提示一样。
- 除非绝对必要,否则避免使用如可重复读或可串行化等强隔离级别,因为它们可能导致锁争用和死锁。
- 在因锁竞争导致性能问题的情况下,考虑使用乐观隔离级别。
- 乐观的隔离级别是读取已提交快照和快照。
- 乐观隔离级别最适合 TempDB 不受 I/O 限制且 TempDB 卷上有大量可用空间的环境。
- 避免通过增加额外硬件来解决性能问题。应尝试诊断问题的根本原因并加以解决。



