第九章 实例和数据库管理
本章涵盖
- 常见的维护错误和误解
- 容量规划
- 数据库损坏
- 管理脚本
- 补丁
在本章中,我们将讨论偶然成为数据库管理员(DBA)的人常犯的维护和配置错误。作为本主题的一部分,我们将讨论在查看事务日志文件相关的一些误解之前,自动收缩数据库的影响,这些误解可能导致性能下降等问题。
接下来,我们将讨论容量规划。这是许多数据库管理员未能执行的任务,我们将看看潜在的后果。然后,我们将探讨一些关于脚本和自动化的常见错误,包括使用游标以及完全缺乏维护自动化。
最后,我们将探讨未能修补服务器的问题。我们将思考不进行修补的原因及其后果。我们还将讨论如何避免犯下这个错误。
本章的许多主题都集中在数据库管理员的日常工作上。因此,并非所有主题都会直接影响业务。然而,重要的是要记住,这些主题肯定会间接影响业务。例如,如果我们未能进行补丁更新,那么服务器被恶意攻击者攻击的风险就会增加,从而导致业务的巨大中断和声誉损害。
变化的是我们与业务团队的互动。到目前为止,我们讨论的大多数活动都是由业务团队主导的。相反,本章中的许多主题将由DBA团队主导,以避免或解决对业务的操作影响。例如,日志碎片化这样的问题并不是业务团队熟悉的,也不会要求我们去解决。相反,我们会持续关注这类问题,因为如果我们不关注,业务就会间接受到性能问题的影响。
对于本章中需要数据库的示例,我们将使用 MarketingArchive 数据库。要创建此数据库,您需要我们在第 4 章中创建的 Marketing 数据库。对于使用 SQL Server 实例的示例,我建议使用托管 Marketing 数据库的实例,尽管这不是必需的。
错误43# 自动收缩数据库
大多数IT专业人员都遇到过这样的情况:某个卷的磁盘空间快用完了,他们不得不进行手动维护以清理旧数据,避免卷被填满。许多数据库专业人员也遇到过这样的情况:他们曾请求存储区域网络(SAN)管理员扩展卷的大小,却只听到对方用牙齿吸气的声音,因为SAN的容量不足。
此外,大多数数据库专业人员都知道,当在云环境(如 AWS 或 Azure)中构建运行 SQL Server 的虚拟机时,其底层基础设施不归您的组织所有,这意味着扩展存储卷会产生直接成本。
因此,当一个刚接触 SQL Server 管理角色的人意识到有一个功能可以自动收缩数据库、回收未使用的空间时,他们可以被原谅会认为这听起来是一个好主意。我曾多次看到有些临时的数据库管理员在不了解后果的情况下,为他们所有的数据库启用了这个功能。
所以让我们假设 MagicChoc 有一个托管在 Azure 上的 SQL Server 实例。该实例承载四个数据库,具体如下:
- Marketing
- SalesManagerPlus
- TargetManager
- MarketingArchive
数据卷上的磁盘利用率徘徊在75%左右,这也是监控工具中磁盘空间警告的阈值。一位经验不足的数据库管理员响应该警告,在调查过程中发现了自动收缩数据库的选项,并将其打开。然而,仅仅一个小时后,多个应用团队开始提交工单,抱怨他们的应用程序性能急剧下降。这是因为启用自动收缩是一个错误。要理解原因,就必须了解自动收缩的工作原理。
SQL Server 中的一个后台任务会定期唤醒并检查是否有启用了自动收缩的数据库。如果有,它会找到第一个配置为自动收缩的数据库,并检查是否有可以回收的空闲空间。如果有,它将对该数据库执行收缩操作。任务然后会再次进入休眠状态。当它几分钟后再次唤醒时,它会检查并收缩(如果需要)下一个配置为自动收缩的数据库。它会永久以这种方式继续,以轮询模式在数据库之间移动。
当数据库执行自动收缩操作时,它将获取锁,这可能会导致需要获取锁的应用程序出现阻塞。如果配置了锁超时,这可能会导致性能问题甚至超时。
收缩操作也是资源密集型的。当收缩进行时,CPU 使用率可能会大幅增加,这可能会影响其他操作,尤其是在使用其他 CPU 密集型功能(如加密或压缩)的情况下。磁盘子系统也会非常繁忙,你可能会看到磁盘活动大幅增加,这可能会对应用程序造成额外的性能问题。这种情况由于收缩操作是完全记录的而被加剧,这意味着事务日志文件和数据文件的吞吐量将会很大。
在收缩操作完成后,一般数据库性能很可能会受到一种称为索引碎片的问题的负面影响。这种碎片是由于收缩操作重新组织数据文件内的页所引起的。然而,我们在这里不会详细讨论这个问题,因为我们将在下一节中详细讨论它。
虽然自动缩小数据库听起来是一个很有吸引力的想法,以保持磁盘空间的可控,但进行容量规划以确保数据量适当是一个更好的主意。本章后面我们将讨论容量规划。
下面列表中的查询可用于检查您是否有开启自动收缩的数据库。
SELECT
name
, is_auto_shrink_on
FROM sys.databases ;
可以使用 ALTER DATABASE 语句关闭自动收缩。以下清单中的查询会关闭 Marketing 数据库的自动收缩。
ALTER DATABASE Marketing
SET auto_shrink OFF WITH NO_WAIT ;
提示: 在第8章中,我们讨论了使用所需状态配置来执行配置最佳实践。如果你采用配置管理方法,那么强制关闭自动收缩是自动化的一个很好的候选项。
错误44# 在数据文件收缩后未能重新构建索引
在前一节中,我们讨论了为什么启用数据库的自动收缩不是一个好主意。然而,SQL Server 管理员也有能力手动收缩数据库或文件。作为一般规则,即使是手动收缩数据文件,也应避免。有些情况下,手动收缩数据库可能是有帮助的。
提示:缩小日志文件有不同的注意事项,我们将在本章后面讨论。
考虑上一节中讨论的 SQL Server 实例。它托管了四个数据库,并运行在 Azure 虚拟机上。其中一个数据库名为 MarketingArchive,用于存储历史营销数据。该数据库已运行很长时间,现在存储了九年的历史数据。业务需求只是存储最近三年的数据。数据卷已使用到 75% 的容量,因此有两种选择。要么扩展数据卷,要么从 MarketingArchive 数据库中回收六年的数据。如果扩展数据卷,将产生额外的 Azure 存储费用,而且存储的数据已不再需要。因此,在这种情况下,清除不再需要的数据并对数据库执行一次性收缩操作以回收空间是合理的。
在这种情况下,数据库管理员删除数据并收缩数据文件。他们知道在收缩操作进行时会有性能开销,所以他们在维护窗口期间执行此操作。
不幸的是,在操作完成后,用户开始抱怨系统性能下降,并且他们的许多查询比平时花费更长的时间才能完成。造成这种情况的原因是数据库中的索引已变得碎片化。为了理解这一点,让我们跟随数据库管理员缩小数据文件的路径,并探索操作期间发生了什么。但首先,让我们先回顾一下页面拆分和索引碎片的核心概念。
数据被存储在一系列 8 KB 的页面中,一系列连续的八个 8 KB 页面被称为一个区间(extent)。构成索引的数据页面存储在一个双向链表中。这意味着每个页面都存储一个指向下一个页面和上一个页面的指针。当一个数据页面变满时,下次 SQL Server 需要向该页面添加数据时,就必须创建一个新页面。这被称为页面拆分。页面拆分有两种类型,被称为“良性页面拆分”和“恶性页面拆分”。
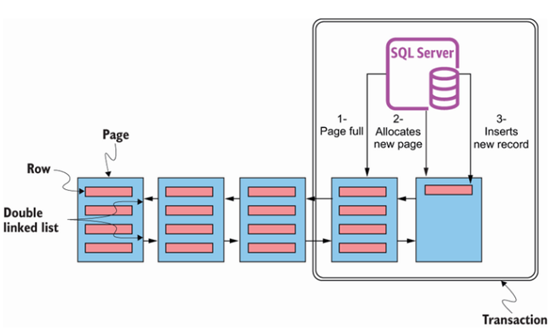
要理解一个好的页面拆分,请参考图9.1中的示意图。该图说明了一个已满的索引。SQL Server 需要在最后一页插入一行新数据,但没有可用空间。因此,从区分配置中分配了下一页,并将新行插入到新页面上。
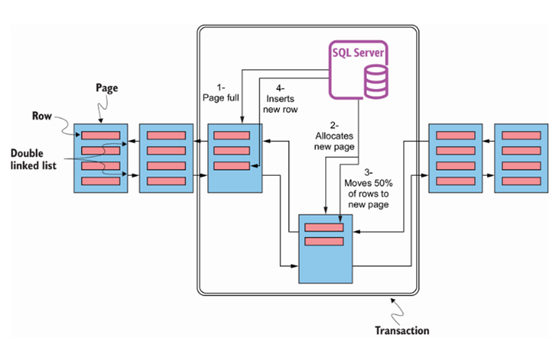
当 SQL Server 需要拆分位于索引中间的页时,如果发生插入或扩展更新,就会发生不良页拆分。当这种情况发生时,SQL Server 必须创建的页将会乱序。当页乱序时,这被称为外部碎片。此外,为了在原始页上腾出空间,原始页的一半行将被移动到新页。这被称为内部碎片,并可能导致 SQL Server 必须读取更多的页才能返回相同数量的数据。不良页拆分如图 9.2 所示。
在我们进一步探讨此情景之前,如果您希望跟随本节的示例,请使用清单9.3中的脚本来构建并填充MarketingArchive数据库。
注意:清单 9.3 中的脚本依赖于我们在第 6 章创建的 Marketing 数据库。
CREATE DATABASE MarketingArchive ;
GO
USE MarketingArchive ;
GO
CREATE TABLE dbo.ImpressionsArchive (
ImpressionID BIGINT NOT NULL IDENTITY PRIMARY KEY,
ImpressionUID UNIQUEIDENTIFIER NOT NULL,
ReferralURL VARCHAR(512) NOT NULL,
CookieID UNIQUEIDENTIFIER NOT NULL,
CampaignID BIGINT NOT NULL,
RenderingID BIGINT NOT NULL,
CountryCode TINYINT NULL,
StateID TINYINT NULL,
BrowserVersion BIGINT NOT NULL,
OperatingSystemID BIGINT NOT NULL,
BidPrice MONEY NOT NULL,
CostPerMille MONEY NOT NULL,
EventTime DATETIME NOT NULL,
) ;
DECLARE @Numbers TABLE (
Number INT
) ;
INSERT INTO @Numbers
VALUES (-1),(-2),(-3),(-4),(-5),(-6),(-7),(-8),(-9) ;
INSERT INTO MarketingArchive.dbo.ImpressionsArchive (
ImpressionUID,
ReferralURL,
CookieID,
CampaignID,
RenderingID,
CountryCode,
StateID,
BrowserVersion,
OperatingSystemID,
BidPrice,
CostPerMille,
EventTime
)
SELECT
ImpressionUID,
ReferralURL,
CookieID,
CampaignID,
RenderingID,
CountryCode,
StateID,
BrowserVersion,
OperatingSystemID,
BidPrice,
CostPerMille,
DATEADD(YEAR, n.Number, i.EventTime)
FROM Marketing.Marketing.Impressions i
CROSS JOIN @Numbers n ;
CREATE NONCLUSTERED INDEX EventTimeNCI
ON dbo.ImpressionsArchive(EventTime) ;
CREATE NONCLUSTERED INDEX ImpressionUIDNCI
ON dbo.ImpressionsArchive(ImpressionUID) ;
让我们首先使用 sys.dm_db_index_physical_stats 动态管理函数 (DMF)。该对象返回索引碎片的详细信息,并按定义的顺序接受以下参数:
- Database ID
- Object ID of the table
- Index ID of the index within the table
- Partition number
- Mode
当 NULL 值传递给 object_id、index_id 和 partition_number 时,将分别返回所有对象、索引和分区的结果。mode 参数指定结果的准确级别,同时与执行时间存在权衡。LIMITED 是最快但最不准确的模式。此模式仅通过查看 B 树的非叶子级别来生成统计信息。SAMPLED 模式将基于索引中 1% 的页面生成统计信息,而 DETAILED 模式将扫描 B 树的所有页面来生成统计信息。
DMF会为范围内每个索引的B树的每个级别返回一行。这对于聚集索引和非聚集索引都是正确的。
我们可以通过执行清单 9.4 中的查询来获取外部碎片量的基线。此查询使用 sys.dm_db_index_physical_stats DMF 返回每个索引的碎片统计信息。它还连接到 sys.indexes 系统视图以获取索引的名称。index_level_size_MB 列是通过将索引级别中的页数除以 128 生成的。这是因为 1 MB 可以存储 128 个 8 KB 的页。avg_fragmentation_in_percent 列返回外部碎片量。我们还过滤掉大于 0 的级别。这意味着我们只会返回每个索引的叶级。
提示:在 DMF 中有一列名为 avg_page_space_used_in_percent,可以告诉我们内部碎片的数量。这在本节中不是重点,但我们将在第 11 章探讨内部碎片。
SELECT
OBJECT_NAME(ips.object_id) AS table_name
, i.name AS index_name
, ips.index_type_desc
, ips.index_level
, ips.page_count
, ips.page_count /128 AS index_level_size_MB
, ips.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(‘MarketingArchive’), NULL, NULL, NULL, ‘Detailed’) ips
INNER JOIN sys.indexes i
ON i.object_id = ips.object_id
AND i.index_id = ips.index_id
WHERE index_level = 0 ;
您会注意到,每个索引的 avg_fragmentation_in_percent 值都非常低。在我的结果中,聚集索引和 EventTimeNCI 索引都是 0.01%,而 ImplessionUIDNCI 索引为 0.12%。然而,根据 SQL Server 实例可用的核心数以及其他因素(例如数据库中是否有其他事务正在运行),您的结果可能会有所不同。
既然我们都准备好了,让我们按照 MagicChoc 数据库管理员会采取的相同步骤操作。首先,我们将删除九年来不需要的数据;然后,我们将对数据文件执行收缩操作。用于清除旧数据的查询可以在以下清单中找到。
DELETE
FROM dbo.ImpressionsArchive
WHERE EventTime < ‘20200101’ ;
现在让我们使用下面列表中的查询来看看我们可以清理多少可用空间。
USE MarketingArchive ;
GO
SELECT
name
, AvailableSpaceMB
, CurrentSizeMB
, (CurrentSizeMB – AvailableSpaceMB) * 1.2 AS TargetSizeMB
FROM (
SELECT
name
, size / 128 – CAST(FILEPROPERTY(name, ‘SpaceUsed’) AS INT) / 128 AS AvailableSpaceMB
, size / 128 AS CurrentSizeMB
FROM sys.database_files
WHERE type = 0
) df ;
虽然你的情况可能会有所不同,但当我运行这个时,我看到我的目标空间(包括 20% 的自然增长)为 838.8 MB。获得这些信息后,我们现在将使用 DBCC SHRINKFILE 命令缩小数据库的数据文件。在清单 9.7 中,我们将数据文件的逻辑名称和目标大小传递给此命令。我们还使用了 WAIT_AT_LOW_PRIORITY 选项。如果长时间运行的查询阻止该命令获取模式锁,此操作将在 1 分钟后超时。此选项是 SQL Server 2022 中的新功能,有助于减轻对应用程序产生不利影响的风险。
DBCC SHRINKFILE (‘MarketingArchive’ , 838) WITH WAIT_AT_LOW_PRIORITY ;
GO
如果我们现在重新运行清单 9.6 中的查询,我们会看到我们的数据库大约是目标大小。因此,一切似乎都按预期工作,但错误在于没有理解这对我们索引碎片化的影响。
如果我们重新运行清单 9.4 中的查询,我们会看到我们的一些或所有索引的碎片率接近 100%,这意味着索引的页面完全乱序,这会导致对进行顺序读取的查询(例如索引扫描)产生性能问题。
提示: 一个常见的误解是,碎片化索引会导致所有查询的性能问题。这不是真的。返回单行的查找操作不会受到影响。性能下降会出现在执行跨多个页面的索引扫描操作或索引查找操作的查询中。
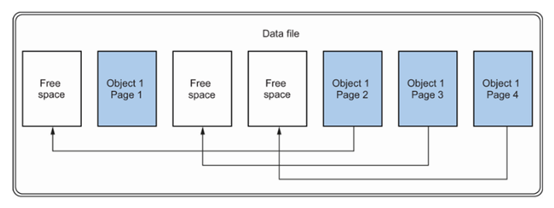
要理解这是为什么,让我们来讨论图9.3中的图表。该图表展示了发生的缩减操作。这个过程从文件的末尾开始,每次遇到一个页面时,就将其移动到文件中的第一个可用空间。对于许多对象来说,这涉及完全颠倒页面顺序,从而导致大量的碎片化。
因此,在必须缩小数据文件的情况下,缩小操作完成后,你应始终重建所有索引。实现这一点的最简单方法可以在清单 9.8 中看到,尽管我们将在第 11 章中探讨另一种方法。该命令执行一个内置存储过程,该过程循环访问数据库中的每个表。它传递一个语句以重建表上的所有索引,并使用 ? 作为表名的通配符值。
EXEC sp_msforeachtable ‘ALTER INDEX ALL ON ? REBUILD’ ;
不应定期缩小数据文件。只有在确有需要的情况下,才能将其作为一次性操作进行。如果确实需要缩小数据文件,操作后重新构建所有索引非常重要。这将避免与严重索引碎片相关的性能问题。
错误45# 依赖自动增长
默认情况下,如果 SQL Server 的某个文件空间不足,它将自动以 64 MB 的块增长文件。默认情况下,数据文件可以增长直到其所在卷已满,而日志文件可以增长到 2 TB 或直到卷已满。使用这些默认设置可能会导致数据文件和日志文件出现问题。
MagicChoc 的 MarketingArchive 数据库是一个大型数据库,当执行抽取、转换和加载(ETL)过程并从 Marketing 数据库中提取历史数据时,每天大约增长 5 GB。一些事务非常大,并且事务是并行运行的。这导致数据文件和日志文件都会发生自动增长事件。DBA 团队使用了默认的自动增长设置。
ETL 过程需要很长时间才能完成,分析显示,随机过程,其中一些非常小,也需要很长时间才能完成,并阻碍其他事务的完成。这是因为依赖自动增长来管理文件大小是一个错误。
在任何情况下,依赖自动增长来管理文件大小都可能是有问题的。文件增长会占用磁盘和处理器资源。此外,如果事务必须增长日志文件,那么在增长操作和数据修改完成之前,它将阻止其他事务写入日志文件。
在数据库的数据文件使用默认的 64 MB 增长设置,而数据库每天增长 5 GB 的情况下,这只会加剧开销带来的问题。此外,这种文件小幅增长的模式可能导致磁盘碎片,这也可能对传统旋转磁盘上的顺序读操作造成性能问题。允许日志文件以小增量增长可能导致事务日志碎片化,我们将在本章后面深入探讨这一点。
当文件增长时,必须“清零”文件中的新空间。这实际上是向文件中写入零,直到文件被填满。这占据了文件增长的大部分开销,可以通过使用即时文件初始化部分缓解,这将在第10章讨论。
我是在建议关闭自动增长吗?不,绝对不是。我坚信应该开启自动增长,但它应当作为数据库意外快速增长时的安全保障,而不是用来日常管理文件大小的手段。
提示:在日常管理中,我们应该根据数据文件和日志文件的预期增长来预先设置它们的大小。然后,我们应使用自动增长功能来应对任何意外情况。我们还应根据数据库的大小调整文件增长的增量。例如,我们预计 MarketingArchive 数据库每天增长 5 GB。因此,如果我们将增长增量设置为 5 GB,那么每日夜间运行的 ETL 过程可以在一天内只增长一次文件。然后,只要我们监控文件增长,就能在第二天早上发现任何异常并进行调查。这种方法可以防止 ETL 过程因文件满而中断,同时也给我们提供了实施战略性修复的机会。
以下列表中的语句将配置 MarketingArchive 数据库中的数据文件以 5 GB 的块增长。
ALTER DATABASE MarketingArchive
MODIFY FILE ( NAME = ‘MarketingArchive’, FILEGROWTH = 5GB ) ;
如果我们要更改模型系统数据库中文件的增长增量,那么这将成为在该实例上创建的新数据库的默认增长增量。当然,我们仍然可以在创建数据库时通过在 CREATE DATABASE 语句中指定 WITH FILEGROWTH 来覆盖此设置。实际上,我强烈建议养成在创建数据库时始终包含文件大小和文件增长设置的习惯,尤其是在生产环境中。
我们不应该允许自动增长在日常管理我们的数据和日志文件的大小。应该启用自动增长,但文件应根据容量规划预先设定大小。自动增长应仅作为应急措施。
错误46# 使用多个日志文件
SQL Server 允许一个数据库拥有多个数据文件和多个日志文件。在某些情况下,将数据分成多个文件可能是有利的。具体来说,它可以有助于并行处理,减少系统页面的争用,并使数据库更容易迁移。它还可以辅助高级恢复策略。
那么日志文件呢?让我们来看一个 MagicChoc 的例子。MarketingArchive 数据库在每晚的 ETL 运行过程中会接收来自多个并行事务的数据。ETL 运行得相当慢,检查等待统计信息时,DBA 注意到在 WRITELOG 等待类型上存在明显的等待,这表明在写入事务日志时存在性能问题。因此,DBA 决定添加一个额外的日志文件以缓解日志压力并提高性能。然而,这是一个错误。让我们讨论原因。
与数据文件不同,将事务日志拆分成多个文件没有任何优势。日志记录总是按顺序写入。这意味着如果我们在事务日志中添加额外的日志文件,SQL Server 仍然会将所有事务写入第一个日志文件。只有当第一个日志文件满了时,才会使用第二个日志文件。因此,使用多个日志文件在性能上没有优势;然而,使用多个日志文件也不会带来性能上的损失。那么,这种做法真的那么糟糕吗?
当你需要恢复数据库时,会发生这个问题。如果事务日志不存在,那么 SQL Server 需要创建它。如前一节所讨论的,它通常还必须将文件清零。如果你有两个事务日志文件,那么它需要清零两个文件而不是一个。这会导致恢复时间增加。
我们唯一应该考虑使用多个日志文件的情况,是当我们发现事务日志已占满卷上的所有可用空间时,作为临时解决方案。在这种情况下,可以在不同的卷上创建第二个日志文件,以便数据库操作可以继续进行,这是可以接受的。
如果我们采取这种方法,我们应该仅将其作为短期措施,同时实施更具战略性的解决方案。这可能涉及扩展原始日志文件所在的卷;将日志移动到一个新的、更大的卷;或者在某些情况下,探究日志为什么会增长得如此之大。可能存在潜在问题,例如备份无法正常工作。
MagicChoc 的 DBA 在 ETL 运行中应该做些什么不同的操作来提升性能?这里没有硬性规定,但在我们的场景中,我们有一个数据仓库通过 ETL 运行被填充的模式,很有可能会发生批量插入。这是因为数据仓库通常从联机事务处理(OLTP)风格的数据库或其他来源按计划批量加载数据,通常是在夜间。
如果情况如此,我们可以考虑在 ETL 运行开始时将数据库的恢复模式更改为大容量日志记录。这将导致大容量操作的日志记录最小化。这将减少写入事务日志的日志记录数量。其结果是使用的日志空间更少,并且事务日志所需的 I/O 吞吐量也会减少,从而减轻磁盘子系统的压力。在 ETL 运行结束时,我们将把恢复模式设置回完整,并进行事务日志备份。
切换回完整恢复模式并进行日志备份很重要,因为大容量日志恢复模型不支持时间点恢复。这意味着在恢复场景中,我们只能恢复到事务日志备份的结束点。我们无法恢复到中间的某个时间点。
可以使用下列清单中的语句将 MarketingArchive 数据库的恢复模型更改为大容量日志恢复模型。
ALTER DATABASE MarketingArchive SET RECOVERY BULK_LOGGED WITH NO_WAIT ;
提高 I/O 性能的另一个选项可能是将日志移动到更快的磁盘。许多 SAN 管理员对所有卷使用 RAID-5 或 RAID-6 的统一策略。然而,由于对事务日志的写入具有顺序性,最佳的 RAID 级别是 RAID-1。
注意:SAN 管理员并不总能支持多种 RAID 级别。
总之,数据库应该只有一个事务日志文件。拥有多个事务日志不会提高性能,反而可能增加恢复时间。如果日志卷空间不足,我们可以在不同的卷上创建第二个日志文件,但这应仅作为临时解决方法,而不是永久性修复。
错误47# 允许日志变得碎片化
虽然大多数数据库管理员都意识到索引碎片,但很少有人意识到事务日志碎片及其可能引发的问题。让我们来看看 MarketingArchive 数据库。我们使用默认的大小和增长设置创建了该数据库。因此,日志文件最初为 8 MB,如果文件空间不足,它将以 64 MB 的增量增长,最大可达 2 TB。MagicChoc 的数据库管理员保留了这些默认设置。我们在本章前面讨论过,在某些情况下,日志文件的增长可能导致 I/O 增加以及阻塞其他事务。
在这个特定场景中,前提是我们运行的是 SQL Server 2022 或更高版本,并且前提是启用了即时文件初始化(将在第 11 章讨论),日志文件不需要清零,因为它以小的 64 MB 块增长。然而,在这种情况下,使用默认设置允许日志增长是一个错误,因为这会导致日志碎片化。反过来,这可能会导致性能问题。要理解原因,我们需要了解一些事务日志的架构。
在事务日志文件中,SQL Server 会创建几个虚拟日志文件(VLF)。在一个 VLF 内,你会有多个日志块,日志块是日志记录的容器,也是事务日志记录被刷新到磁盘的单位。这些日志记录提供了对数据库中执行的每个数据操作语言 (DML) 和数据定义语言 (DDL) 语句的日志。在完全恢复模式下,所有分配和释放的页和区也会被记录。每条日志记录都会被赋予一个日志序列号(LSN)。LSN 由三个部分组成:首先是 VLF 序列号,其次是日志块 ID,最后是日志记录 ID。
当事务日志被截断时,并不是日志文件本身被截断——而是日志文件所包含的 VLF 被截断。任何不包含活动事务的 VLF 都会被截断。事务可能因为多种原因被标记为活动状态,包括
- VLF 包含尚未完成的交易。
- VLF 包含尚未在可用性组拓扑中流式传输到副本的事务。
- VLF 包含尚未被变更数据捕获收集的事务。
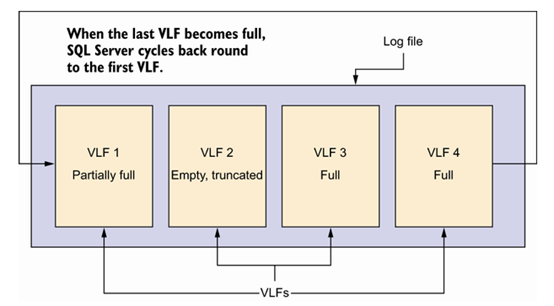
事务日志文件从未被完全截断;始终至少有一个活动的 VLF,但在任何给定时间可能有多个活动的 VLF。
事务日志文件具有循环性质。当日志文件中的最后一个 VLF 填满时,SQL Server 会循环到事务日志的前端,并开始使用已被截断的第一个 VLF。如图 9.4 所示。
如果日志文件中没有截断的 VLF,当最后一个 VLF 填满时,SQL Server 将根据该文件的自动增长设置尝试增长日志文件。如果由于增长设置不允许或底层存储已满而无法增长文件,则会抛出 9002 错误,表示事务日志已满。
当日志文件增长时,将创建的 VLF 数量取决于当前事务日志的大小以及其增长的增量。用于确定将创建多少个 VLF 的规则指出,如果增长增量小于当前日志大小的 1/8,将创建一个 VLF。否则:
- 如果增量小于64 MB,将创建四个VLF。
- 如果增量在 64 MB 到 1 GB 之间,将创建八个 VLF。
- 如果增量大于1 GB,将创建16个VLF。
这个公式可能导致日志文件包含非常大量的 VLF。日志碎片化是指事务日志内部拥有不成比例数量的 VLF。这可能在还原数据库、附加数据库以及 SQL Server 实例启动时恢复数据库时导致性能问题。它还可能对像 AlwaysOn 可用性组这样的技术造成性能问题。
日志文件应包含多少个 VLF 并没有固定的数量,但如果超过 1,000 个,它们通常会开始引发问题。每个数据库都必须根据自身情况来考虑,但我通常的目标是每 GB 日志文件总大小大约有两个到四个 VLF。我们还应该避免一次性扩展大型日志文件超过 8 GB,因为 VLF 太少也可能导致问题。
清单 9.11 中的查询可用于确定 MarketingArchive 数据库是否有碎片化的日志文件。子查询通过查询 sys.dm_db_log_info DMF 来计算指定数据库的 VLF 数量。外部查询将这些结果与 sys.master_files 系统视图连接,并执行一些简单的计算,将文件大小从 KB 转换为 GB,并计算 VLF 的最小和最大理想数量。
SELECT
li.database_id
, li.ActualVLFs
, mf.size/1024/1024 AS SizeInGB
, mf.size/1024/1024*2. AS MinIdealVLFs
, mf.size/1024/1024*4. AS MaxIdealVLFs
FROM (
SELECT database_id, COUNT(*) AS ActualVLFs
FROM sys.dm_db_log_info(DB_ID(‘MarketingArchive’))
GROUP BY database_id
) li
INNER JOIN sys.master_files mf
ON li.database_id = mf.database_id
WHERE mf.type = 1 ;
如果你发现需要解决日志文件碎片问题,应通过备份日志文件(如果数据库使用的是完整恢复模型)或截断日志文件(如果数据库使用的是简单恢复模型)来清理日志文件。然后,我们需要使用 DBCC SHRINKFILE 将文件缩小到尽可能小。最后,我们可以根据事务日志的目标大小,将增长增量设置为适当的值。
我们应该始终尝试防止日志变得碎片化。如果这种情况发生,在执行还原操作或使用可用性组等功能时,我们可能会遇到性能问题。我们可以通过缩小日志文件然后使用适当的增量允许其增长来消除现有的碎片化。
错误48# 未能进行容量规划
容量规划是估算应用程序在特定时间段后所需资源数量的过程。这个时间段通常与组织的硬件更新周期一致。例如,假设 MagicChoc 的硬件更新周期为三年。在该周期的两年时,开发了一个新的应用程序,它将在公司数据中心的虚拟机上运行。在这个项目的容量规划阶段,任务是估算该应用程序在一年后将需要多少计算、内存和存储资源。这将帮助组织判断其存储区域网络(SAN)和虚拟化集群中是否有足够的资源来运行该应用程序直到下一次硬件更新,或者是否需要采购新的硬件。
一年之后,在硬件更新周期结束时,又一次容量规划操作将需要进行。这一次,任务是确定应用程序在三年后需要的资源量。这将告知组织在更新中需要购买多少额外的计算能力和 SAN 容量。
让我们采用我们刚刚讨论过的场景,看看为什么不进行容量规划是一个错误。我们正处于硬件生命周期的第二年,并且刚刚推出了历史营销分析应用程序。正在开发的MarketingArchive数据库被提升到生产环境中,数据文件的大小为200 GB。我们注意到数据文件中有50 GB的可用空间,因此我们认为自然增长有足够的空间,而且因为我们很忙且容量规划很困难,所以我们决定不参与这个过程。
我们未能意识到的是,数据库每天会拉取 5 GB 的数据,并且有三年的数据保留策略。这意味着,在一年之后,到硬件生命周期结束时,数据库中的数据文件总量将达到 1.78 TB。我们还未能考虑 TempDB 系统数据库和事务日志需要多大。考虑到事务日志和 TempDB 所需的空间,再加上为意外增长预留足够的余地,在像这样的大型数据仓库环境中,你很可能需要约 3.2 TB 的空间。更大的问题是,企业 SAN 上只剩下 2 TB 的可用容量,而这部分容量已经预留给提交了容量需求的应用程序。
这种情况很可能会导致与业务部门进行一次非常困难的对话。它还可能导致一段长时间的停机,因为存储团队需要订购和安装额外的 SAN 容量。显然,不进行容量规划是一个错误,但这是我惊人频繁见到的一种情况。
为了避免这个错误,数据库管理员团队应当与开发团队合作,估算未来的需求。计算这个应用程序数据文件的存储容量需求非常简单。该应用程序每天消耗大约 5 GB 的数据,这是我们所说的线性增长模式,如图 9.5 所示。
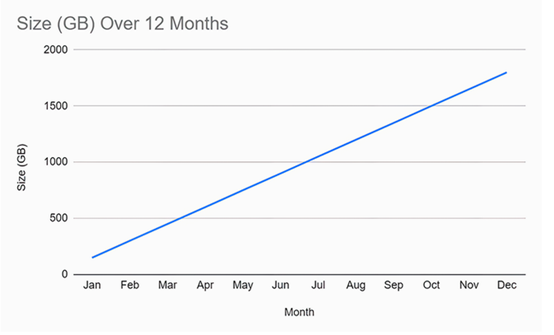
然而,想象一下,如果数据的消费量不是以固定的速度增长,而是每个月翻一番。我们看到的将不是线性增长模式,而是指数增长模式,其特征是“折线曲线”。如图9.6所示。
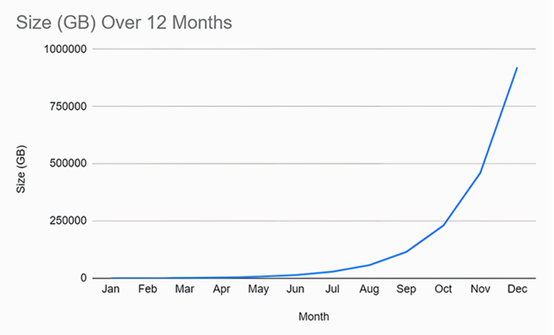
我们用于数据文件的容量规划方法通常与已经运行一段时间的现有系统相关。我们将拥有一系列历史数据点,可以将其绘制成图并向未来进行预测。不幸的是,对于新的(绿色场)应用程序,情况并非总是如此。在许多情况下,我们每天的数据进入率并不均匀。
在这些新的场景中,我们通常需要与业务中的应用程序所有者沟通,并评估预期的业务增长量。例如,如果解决方案是一个销售应用程序,我们可以询问该应用程序第一年的销售预期。
一旦我们从业务中收集到尽可能多的信息,我们就可以定义规则并在数据库中展开数据。例如,在一个新的销售数据库中,我们可以手动为10个客户插入数据,其平均送货地址数量由对业务的采访确定。然后,我们可以为每个客户手动插入一张销售订单。
然后,我们可以根据业务预期展开数据。例如,如果销售预测显示第一年将有5,000名客户入驻,每位客户平均下单10次,那么我们可以使用 CROSS JOIN 和数字表将客户数据按 500 倍复制,将订单数据按 5,000 倍复制。这样我们就可以大致估算数据库的预期规模。
在数据被展开后,对数据库执行典型操作还可以让我们评估 TempDB 数据库和事务日志文件的大小需求。这是一个重要的考虑因素,特别是在数据仓库场景中,因为这些文件所需的空间可能比你预期的要多。根据我的经验,每个文件通常需要占数据库数据文件大小的大约 25%。
同样重要的是要记住,我们需要预留空间。例如,如果我们预计合并的数据文件、日志文件和 TempDB 为 1 TB,那么我们应该再增加 20% 以应对计划外的增长。因此,我们的估算将是 1.2 TB。
提示: 容量规划总是有些凭感觉,这对于新建系统尤其如此。然而,这绝不是浪费时间。有一个关于增长的最佳猜测总比完全没有头绪要好得多。
在云场景中,容量规划的考虑略有不同,但它们仍然同样有效。我们需要记住,虽然我们可以轻松地将实例扩展到更大的规格,拥有更多的内存和计算能力,但这需要重启虚拟机。这意味着对于 24/7 的工作负载,需要有停机时间来增加容量。
有限云
云存储的弹性特性意味着人们倾向于认为云具有“无限容量”,但事实并非如此。实际上,在COVID-19疫情期间,至少有一家主要的云服务提供商在某些地区由于办公迁移导致的云计算激增而出现了容量问题。
一个更大的考虑因素是云财务管理。与倾向于采用资本支出模式的组织数据中心不同,在云环境中我们转向运营支出模式。这意味着超大实例会带来实际成本,并且你可能需要定期与采购团队或云财务管理团队进行沟通,要求将工作负载调整到合适的规模(缩小)。幸运的是,我们可以通过审查云原生工具(如 Azure Advisor 和 AWS Trusted Advisor)提供的尺寸建议主动应对这一点。
这是一个完全合理的考虑,并且与我们刚才讨论的内容相抵触。答案需要由组织根据具体情况来确定,考虑云容量预留、储蓄计划和折扣、承诺支出,以及最终成本与潜在短时中断之间的权衡。
例如,可能会决定将一个具有五个9可用性要求的关键任务系统(我们将在第13章讨论)托管在基于容量规划结果最初配置过大的虚拟机上。与此同时,可能会决定将不太重要的应用程序托管在配置合适的虚拟机上,当它们需要扩展时,停机时间是可以接受的。
总而言之,我们应该始终考虑数据库的容量规划。在本地部署时,我们应通过资本支出视角来看待这一点,而在云端时,我们应通过经营支出视角来看待,并将成本管理纳入我们的规划和决策中。
错误49# 始终将 TempDB 和日志文件放在专用驱动器上
长期以来,人们一直建议将数据文件、日志文件和 TempDB 始终分到不同的卷上,因为这可以提高性能。但这仍然总是正确的建议吗?让我们回到 MagicChoc,更详细地探讨这个问题。
MagicChoc 的所有本地服务器都是虚拟机,其存储托管在 SAN 上。我们已经构建了一台新服务器来托管 MarketingArchive 数据库,并且我们已经建立了一个 SQL Server 实例。按照官方指南,我们已要求存储团队提供三个数据卷和一个系统卷,并将 MarketingArchive 数据文件放在其中一个数据卷上,将 MarketingArchive 日志文件放在另一个卷上,并将 TempDB 放在第三个卷上。
首先,让我们从性能的角度来考虑这个问题。所有三个卷都位于 SAN 上。要访问这三个卷的数据,我们将通过相同的网络接口卡,经过相同的网络路径,并使用相同的 SAN 结构;然后事实表明,所有三个卷都创建在相同的 RAID 阵列上。在这种情况下,我们不会看到性能提升。
但是会有任何负面影响吗?通常,答案是否定的,但我见过一些 SAN 软件要求数据文件和日志文件位于同一卷上,才能执行应用程序一致快照,这在升级系统时非常有用,可以提供一个快速且简单的恢复点。
应用一致性快照
快照是一种特殊类型的备份,位于存储层,使用写时复制技术可以非常快速地对卷进行时间点快照。这些普通快照被称为崩溃一致性快照。它们不适合与 SQL Server 一起使用,因为如果在快照开始时有事务正在进行,在恢复时数据库很可能会被损坏。
与普通快照不同,应用程序一致性快照与卷影拷贝服务集成,会在拍摄快照之前将内存中的数据刷新到磁盘。这意味着,与普通快照不同,即使在快照开始时存在正在进行的事务,它也可用于恢复 SQL Server 数据库。
当然,这并不意味着 TempDB 和日志文件绝不应分离。例如,组织标准可能是将所有数据库存储在 SAN 上;然而,对于特定应用程序,TempDB 可能有非常高的吞吐量要求。在这种情况下,将 TempDB 放在本地 M.2 驱动器上可能是有益的。
总之,如果您的数据库托管在 SAN 上,将数据文件、日志文件和 TempDB 分离到不同的卷上并不会带来性能上的好处。通常这样做不会引起问题,但在少数情况下,这可能会导致无法进行应用程序一致快照。然而,将日志和 TempDB 移动到其他卷上可能还有其他合理的原因。
错误50# 不定期检查损坏
数据库可能会损坏。这是事实。损坏可能由多种问题引起,包括系统突然关闭、存储故障,甚至是恶意活动。数据库损坏是一个噩梦。比数据库损坏更糟糕的事情,莫过于不知道数据库已经损坏。
现在是星期五的晚上,MagicChoc值班的数据库管理员正快要入睡时,电话响了。是一个P1问题。在使用一个关键任务数据库时,一名用户刚刚收到一个错误,他们无法访问所需的数据。
这是任何数据库管理员最不希望遇到的事情,因为他们正在周五晚上休息,而通过定期检查数据库是否损坏,这本可以轻松避免。如果数据库管理员团队能在业务遇到问题之前就发现,也会对企业提供更好的服务。
我们可以通过运行清单 9.12 中的脚本来模拟用户所遇到的问题,从而在 MarketingArchive 数据库中造成损坏。脚本执行的第一件事是备份 MarketingArchive 数据库。运行这一步非常重要,以便您可以从备份中恢复。然后,脚本动态创建一个 SQL 语句,该语句运行 DBCC WRITEPAGE 命令,将随机值写入 ImpressionsArchive 表中的数据页。在进一步操作之前,非常重要的是要理解 DBCC WRITEPAGE 是一个未记录、不受支持且极其危险的功能,它会直接写入数据页,绕过缓冲区缓存。它非常适合测试失败场景,但除非您 100% 确定操作且有数据库备份,否则绝不应使用它。在生产环境中也绝不应使用它。
警告:DBCC WRITEPAGE 很危险。除非您百分之百确定并准备好丢失数据,否则不要使用它。切勿在生产环境中使用。
USE master ;
GO
BACKUP DATABASE MarketingArchive
TO DISK = ‘C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\Backup\MarketingArchive.bak’ ;
GO
ALTER DATABASE MarketingArchive SET SINGLE_USER WITH NO_WAIT ;
GO
DECLARE @SQL NVARCHAR(MAX) ;
SELECT @SQL = ‘DBCC WRITEPAGE(‘ +
(
SELECT CAST(DB_ID(‘MarketingArchive’) AS NVARCHAR)
) +
‘, ‘ +
(
SELECT TOP 1 CAST(file_id AS NVARCHAR)
FROM MarketingArchive.dbo.ImpressionsArchive
CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%)
) +
‘, ‘ +
(
SELECT TOP 1 CAST(page_id AS NVARCHAR)
FROM MarketingArchive.dbo.ImpressionsArchive
CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%)
) +
‘, 2000, 1, 0x61, 1)’ ;
EXEC(@SQL) ;
ALTER DATABASE MarketingArchive SET MULTI_USER ;
GO
如果我们现在对 ImpressionsArchive 表运行 SELECT 语句,我们将看到类似如下的错误:
SQL Server detected a logical consistency-based I/O error: incorrect
checksum (expected: 0x968b1542; actual: 0x96845542). It occurred during a
read of page (1:71224) in database ID 11 at offset 0x00000022c70000 in
file ‘C:\Program Files\Microsoft SQL
Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\MarketingArchive.mdf’.
当然,也有可能错误发生在数据被访问之前,在这种情况下我们根本没有机会发现它,但数据损坏长时间未被发现并不少见。这使得确切找出它发生的时间更加困难,也使得修复它更加困难。
检查数据库损坏就像运行清单 9.13 中的命令一样简单,如果我们自动执行检查并安排其定期运行,我们可以配置我们的监控工具在发现损坏时发出警报。如果发现损坏,该命令将返回错误。
DBCC CHECKDB(‘MarketingArchive’) ;
定期检查数据库是否损坏非常重要。如果能及时发现损坏问题,解决起来会容易得多。如果数据库管理员在业务部门注意到问题之前发现问题,这对业务来说也是一种更好的服务。如果确实发现数据库损坏,那么修复的最佳方法是执行页恢复。这可以将数据丢失降到最低,并且通常可以完全避免数据丢失。如果无法进行页恢复,则可以使用 DBCC CHECKDB 来解决损坏问题,但如果损坏出现在数据页上,将会导致这些数据页上存储的数据丢失。
错误51# 未能实现自动化
我听说过一句话,“优秀的开发者是懒惰的。”这并不是侮辱。相反,这意味着一个优秀的开发者会花两倍的时间去编写可以重复使用的代码,以避免反复编写类似的代码。对于数据库管理员(DBA)也是同样的道理。一个优秀的DBA会花时间尽可能地进行自动化,以避免执行手动任务。我们在第8章已经讨论过SQL Server安装的自动化,但在本节中,我希望我们关注SQL Server维护的自动化。
让我们假设我们的 MagicChoc DBA 大部分 SQL Server 维护都是手动执行的。备份是自动化的,因为这些备份由公司备份工具(例如 Commvault 或 NetBackup)完成,但所有 SQL Server 级别的维护,例如索引重建、统计信息更新和一致性检查,都是 DBA 作为日常工作的一部分来执行的。我见过不止一个 DBA 不小心陷入这个陷阱,但这是一个大错误,原因有很多。
首先,执行平凡、重复的任务真的相当乏味。这可能导致诸如员工流动率增加等问题。其次,是机会成本。如果维护工作自动化,那么数据库管理员可以将时间用于执行更高价值的活动,例如诊断复杂的性能问题。第三,这些任务往往根本不会发生。一个紧急的操作任务出现时,数据库管理员会放下日常维护去处理它。最后,这可能导致人为错误,因为人们在自动驾驶状态下执行重复性任务。
我看到的一个更常见的错误——事实上如此常见,以至于在我遇到的大多数环境中可能都有——就是去中心化的自动化。为了理解这种方法,让我们假设我们的 MagicChoc 数据库管理员厌倦了每天进行手动维护。因此,他们决定引入一些自动化。他们检查每一个 SQL Server 实例,并精心手工制作 SQL Server 代理任务,在每台服务器上执行常规维护。这为什么是一个错误呢?
原因是现在每天早晨,我们的数据库管理员必须逐一查看每个 SQL Server 实例,并查看每个已创建的维护作业的 SQL Server Agent 作业历史。虽然这比实际执行维护工作稍微快一些,但它仍然存在相同的问题。具体来说,这是一项平凡、耗时的手动工作,有时会因为紧急的操作问题而被忽略。
我们如何能做得更好?答案是集中维护。如果一个组织的 SQL Server 系统部署在本地,这可能涉及拥有一个集中管理服务器,该服务器会环绕系统中的每个 SQL Server 实例并执行维护任务。
当我们在用于安装新的 SQL Server 实例的脚本或所需状态配置清单中包含注册步骤时,这种配置效果最佳。然而,它确实有一些复杂性。过去我实施这个时,我需要构建一个简单的调度引擎,使用表、视图和存储过程,以确保正确的作业在正确的实例上按正确的时间表执行。
如果一个组织的 SQL Server 系统在云端,有更优雅的方法来集中进行维护。例如,如果我们的 SQL Server 系统托管在 Azure 上,我们可以使用 Azure runbooks、Azure functions 或逻辑应用程序对 Azure SQL Server 虚拟机进行维护。如果我们的系统是基于 SQL Database 的,弹性作业将是配置维护的一个不错选择。
无论我们决定使用哪种工具,为 SQL Server 实现集中化、自动化的维护都是很重要的。这可以减少人工工作量,并缓解多种问题。这些问题包括员工流动率高、维护工作疏漏,以及与更高价值工作相比的机会成本。
错误52# 将游标用于管理目的
在第5章中,我们从开发的角度讨论了游标,以及为什么我们应该避免使用它们。我见过一些数据库管理员理智地执行不允许使用游标的标准,但自己却在管理脚本中使用游标。通常他们的借口是脚本不会遍历很多对象,所以没关系。
想象一下,我们的 MagicChoc DBA 团队在其环境中执行一项不允许使用游标的标准。他们完全有权这样做,因为他们必须在生产环境中排查性能问题——有时是在非工作时间。然而,他们决定在自己的管理脚本中使用游标。
其中一位开发人员注意到DBA在使用游标,并提出了担忧。他有点恼火,想知道为什么DBA可以使用游标而他的团队不能。DBA向开发人员解释说,他们的脚本不同,因为他们只对少量对象进行迭代,所以性能影响不明显。
开发人员对此提出疑问,指出他的一些查询只需要遍历少量行,所以有什么区别呢?面对这种情况,DBA们勉强决定批准一个例外,允许开发人员使用游标,前提是他们不要遍历大量行。
这会引发滚雪球效应,异常情况从各个角度不断出现。执行禁止光标的策略变得不可能。MagicChoc 最终会有多个光标处理不同数量的行。此外,应用程序会随着时间自然增长,那几行数据会变成大量数据。
所有这些问题本可以通过DBA简单地遵循他们自己的编码标准来避免。只要你理解替代技术,就永远没有充分的理由使用游标。例如,列表9.14中的查询演示了DBA如何使用游标遍历数据库中的每个索引并重建它。
提示:数据库管理员在重建索引时通常会使用条件逻辑。本节中的示例只是简单地重建所有索引。我们将在第11章讨论索引重建的条件逻辑。
DECLARE @Command NVARCHAR(MAX) ;
DECLARE @Table NVARCHAR(256) ;
DECLARE Tables CURSOR READ_ONLY FOR
SELECT name
FROM sys.tables ;
OPEN Tables ;
FETCH NEXT FROM Tables INTO @Table
WHILE @@FETCH_STATUS = 0
BEGIN
SET @Command = ‘ALTER INDEX ALL ON ‘ + QUOTENAME(@Table) + ‘ REBUILD ; ‘ ;
EXEC(@Command) ;
FETCH NEXT FROM Tables INTO @Table ;
END
CLOSE Tables ;
DEALLOCATE Tables ;
注意: 值得注意的是,在本章前面我们使用了 sp_msforeachdb 存储过程来遍历表并重建索引。这个存储过程在内部也使用了游标。
那么我们如何改写这个脚本以使用一种更高效的方法来避免游标呢?答案是使用 XML 数据类型的小技巧,如清单 9.15 所示。子查询生成我们想要运行的命令列表,FOR XML 子句将此列表转换为 XML 格式。然而,由于我们使用的是 PATH 模式且没有 XPath 表达式,它就会变成一个单一的连续节点,没有标记。由于外部查询期望的是 NVARCHAR,XML 会被隐式转换回这种数据类型,以便它可以作为动态 SQL 执行。
DECLARE @SQL NVARCHAR(MAX) ;
SET @SQL = (
SELECT ‘ALTER INDEX ALL ON ‘ + QUOTENAME(name) + ‘ REBUILD ; ‘
FROM sys.tables
FOR XML PATH(”)
) ;
EXEC(@SQL) ;
这个查询不仅更高效,而且代码行数也不到一半。然而,对于小型数据集来说,主要的好处是为开发团队树立良好榜样,以身作则。
使用游标从来没有真正的技术理由。总是有更好的方法。虽然数据库管理员有时会在管理脚本中使用游标,但这给开发者树立了坏榜样,并可能导致逐渐升级的政治问题。相反,数据库管理员应该使用更高效的技术,例如本章中展示的 XML 技巧。
错误53# 未能打补丁
打补丁是一件麻烦事。任何数据库管理员都会告诉你这一点,我也不会争论。总会有面向客户的24/7系统,业务不希望停机,或者有一个数据仓库应用,其ETL运行需要12个小时,并且必须在营业日开始之前完成。
这导致了许多数据库管理员(DBA)、应用团队和应用所有者都会犯的一个错误,那就是避免对他们的“黄金”系统进行补丁更新。那么这个错误会带来什么后果呢?让我们通过一名MagicChoc DBA的视角来看一看。
MagicChoc 有两个数据库系统,但它不进行补丁更新。它什么都不打补丁——操作系统、中间件或 SQL Server 都不打补丁。其中一台服务器是支持在线销售数据库的数据库,需要全天候 24/7 可用。另一台是营销数据仓库。该系统处理大量数据,ETL 过程整夜运行,并且必须在下一个工作日开始前准备好。
在一个寒冷的夜晚凌晨三点,当值的数据库管理员被服务交付经理叫醒。有一个问题——一个大问题。公司里的任何人都无法访问任何数据库。攻击者利用了未打补丁的服务器并获得了横向移动的能力,使他们能够在整个系统中实施勒索软件攻击。
我在2023年11月补丁星期二之后写下这段文字。就在这个月,Windows Server 的累积更新(CU)修复了超过50个安全漏洞。因此,不按月更新补丁是一个巨大的安全风险,会使组织面临各种网络犯罪的威胁。
当我们未能进行补丁更新时,这也会使我们的组织面临其他非安全相关的风险。像微软这样的供应商使用累积更新(CU)来修复漏洞并提供稳定性改进。因此,如果我们不对系统进行补丁更新,发生原本可以避免的停机的可能性就更大。有时,即使是较小的新功能也是通过累积更新发布的,如果我们没有进行补丁更新,就无法利用这些功能。
那么我们如何在满足业务需求的同时确保所有服务器都打上补丁呢?让我们依次看看每种情况。首先,我们将讨论对24/7系统的需求,该系统不能为了打补丁而停机。
如果一个数据库有全天候可用性要求,那么它必须具备高可用基础设施。这意味着使用诸如 AlwaysOn 可用性组的技术,该技术使用日志流在多台服务器之间同步副本数据库,可用于提供灾难恢复或高可用性。当用于高可用性时,在主服务器发生故障时,它将提供数据库的自动故障转移。当用于灾难恢复时,故障转移将需要人工干预。这项技术也可以用于解决补丁问题。
在这种情况下,我们可以为集群中的辅助节点打补丁。一旦它们已经被打过补丁,我们可以在为原本托管数据库的服务器打补丁之前,从主副本执行受控的故障切换到辅助副本。这从技术上确实会导致停机,但停机时间只会持续几秒钟,而不是补丁窗口可能持续几个小时。从最终用户的角度来看,这种停机是非常短暂的,通常只不过是一个瞬间。
第二种情况是数据仓库,其 ETL 运行需要整晚完成,并且必须在早晨前完成。数据仓库可能不适合使用可用性组,我们将在第13章进一步讨论,但它可以托管在集群实例上。故障转移集群实例(FCI)将数据库托管在集群中多个节点共享的存储上。这意味着如果一个节点发生故障,另一个节点可以自动接管数据库,从而提供自动故障转移。然而,即使使用了 FCI,即使是大约 30 秒的短暂停机(这是 FCI 故障转移所需的平均时间),也可能对 ETL 运行造成严重问题。
因此,解决补丁问题的方法简单归结为时间安排。对于数据仓库来说,在工作时间内出现30秒的停机可能是可以接受的。如果是这种情况,那么我们可以使用类似于我们为可用性组描述的滚动更新方法。不同之处在于,停机时间将安排在工作时间内,而不是在活动最少的时间段。
如果这不是一个选项,通常在周末会有一段时间,系统例如数据仓库要么不使用,要么同时使用的人很少。在这种情况下,我们只需将停机安排在周末发生。
总而言之,我们始终必须允许我们的服务器进行补丁更新,即使是对任务关键的黄金系统也是如此。不打补丁的风险远远超过定期每月补丁周期带来的不便。
总结:
- 缩小数据库将导致索引接近100%的碎片化。
- 永远不要自动收缩数据库,因为这会导致性能下降和资源使用增加的无限循环。
- 如果我们必须手动缩小数据库,那么我们必须记得在操作完成后重建所有索引。
- 永远不要依赖自动增长来管理数据库大小,因为这可能导致性能问题。
- 不要使用多个日志文件,因为这没有任何好处。如果有多个事务日志文件,第一个文件会在使用第二个文件之前先填满。
- 交易日志中存储的每个事务都会分配一个 LSN。LSN 用于标识事务,由 VLF、日志块和事务 ID 组成。
- 事务日志文件包含多个 VLF。当日志文件增长时,会自动创建额外的 VLF。
- 拥有过多的 VLF 被称为日志碎片化,并可能导致性能问题。
- 内部索引碎片化指的是索引的每一页被填充的程度。
- 外部索引碎片化是指索引中有多少页的顺序不正确。
- 要消除日志碎片,我们必须缩小事务日志,然后允许它以更大的增量增长。
- 索引元数据可以在 DMV 和 DMF 中找到。
- 在检查索引分片时,有一个特别有用的 DMF,叫做dm_db_index_physical_stats。这个 DMF 可以为给定数据库中每个索引的每一层返回一行数据。
- 未能进行能力规划可能会导致业务问题,例如意外支出。如果新硬件的交付时间较长,还可能导致停机。
- 在进行容量规划时,我们会尝试寻找增长模式,例如线性增长或指数增长。
- 将数据库文件、事务日志文件和 TempDB 放在不同的卷上并不总是必要的。
- 如果我们的所有数据都存储在 SAN 上,那么多个卷位于相同的物理 RAID 阵列上是很常见的。
- 我们应定期检查数据库是否损坏,数据库损坏可能由多种问题引起,例如磁盘错误。
- 及早修复数据库损坏比长时间未发现损坏更容易,且数据丢失的风险更小。
- 尽可能始终寻求自动化。自动化可以减少人工劳动和人为错误。它还允许数据库管理员执行更高价值的任务,例如调查性能问题。
- 数据库管理员不应该使用游标。相反,他们应该以身作则,向开发团队展示总有更高效的做事方式。
- 即使是黄金系统也应打补丁。我们不应允许任何服务器被排除在定期打补丁之外。
- 我们可以使用诸如 AlwaysOn 可用性组或故障转移群集实例等技术来减少补丁维护的停机时间。
- 我们可以通过创造性的安排来解决许多补丁挑战。



