第五章 T-SQL开发
本章涵盖
- 可能导致意外结果的错误
- 可能导致性能问题的错误
- 在T-SQL中避免使用游标循环
- 删除大量行的操作
SQL 是一种 ANSI 和 ISO 标准语言,允许数据库开发人员查询和操作关系数据库中的数据。T-SQL 是 SQL Server 的 SQL 语言方言,用于与 SQL Server 实例及其所托管的数据库进行交互。
在第4章中,我们为新的MagicChoc数据库设计并创建了表格。在本章中,我们将探讨一些较少经验的开发人员在T-SQL中可能犯的一些常见错误。作为T-SQL开发的示例,我们将参考MagicChoc,它希望我们开发将被其前端应用程序使用的逻辑。我们将利用这个机会开始探讨一些较少经验的开发人员在T-SQL中可能犯的一些常见错误。
对于更熟悉使用诸如 C 这样的语言编写应用程序代码的开发者来说,掌握 SQL 可能是一项挑战
T-SQL 中的大多数开发错误都会导致性能问题,这将是本章的主要关注点。然而,前两节将关注导致意外结果的错误。最后,我们将看一个在删除大量行时常见的错误。
错误14# 错误处理 NULL 值
MagicChoc 已要求我们查看数据并确认有多少产品子类别没有描述。因此,我们在以下清单中运行了查询。
SELECT COUNT(*)
FROM dbo.ProductSubcategories
WHERE ProductSubcategoryDescription = NULL ;
返回的结果是 0。太棒了。每个产品子类别都有描述,对吧?我们知道总共有 16 个子类别,所以让我们通过反转查询来再次检查结果,计算描述不为 NULL 的行数,使用以下列表中的查询。
SELECT COUNT(*)
FROM dbo.ProductSubcategories
WHERE ProductSubcategoryDescription <> NULL ;
等一下!这个查询的结果也返回了 0。这到底是怎么回事?一些刚接触 SQL 的开发者有时没有意识到,NULL 是一个未知值。因此,在比较中,NULL 不等于另一个 NULL。
要理解这一点,请考虑以下类比。我们的银河系中有多少颗星星?就我个人而言,我不知道这个答案。世界上有多少颗沙粒?同样,我个人也不知道。这是否意味着银河系中的星星数量等于世界上的沙粒数量?不,当然不等。可能相等,也可能不等。我不知道。因此,就像我不能说两个我不知道的数值是相同还是不同一样,SQL Server 也不能告诉我们两个它不知道的数值是相同还是不同。
为了解决这个问题,我们只需要在处理 NULL 值时调整语法,使用 IS 或 IS NOT,而不是 = 和 <>。例如,下面列表中的脚本成功返回了没有描述的产品子类别的计数,随后返回了有描述的产品子类别的计数。
SELECT COUNT(*)
FROM dbo.ProductSubcategories
WHERE ProductSubcategoryDescription IS NULL ;
SELECT COUNT(*)
FROM dbo.ProductSubcategories
WHERE ProductSubcategoryDescription IS NOT NULL ;
处理 NULL 值的另一个方面,可能会让 SQL 新手感到困惑,是使用 IS NULL 与 ISNULL() 函数。如我们刚刚所见,IS NULL 用于 WHERE 子句中以筛选结果集,使其仅返回列中包含 NULL 值的行。
另一方面,ISNULL() 函数用于 SELECT 列表、JOIN 子句或 UPDATE 语句的 SET 子句中,以将 NULL 值替换为非 NULL 值。例如,下面列表中的查询将返回完整的产品子类别列表,但 NULL 的描述将被替换为“无可用描述”这个值。
SELECT
ProductSubcategoryName
, ISNULL(ProductSubcategoryDescription, ‘No description available’)
FROM dbo.ProductSubcategories ;
在处理 NULL 值时始终要小心。请记住,NULL 值不等于另一个 NULL 值。还要记住,IS NULL 语法用于筛选查询以返回 NULL 值,而 ISNULL() 函数用于将 NULL 值替换为非 NULL 值。
错误15# 将 NOLOCK 用作性能优化
MagicChoc 的销售应用程序有一个下拉框,里面填充了与客户相关的地址,这允许销售人员选择他们希望订单送达的收货地址。然而,当收货地址屏幕加载时,下拉列表加载很慢,我们被要求改进查询的性能。
我们听说在 SQL Server 中,锁定和阻塞可能会导致性能问题,有人提到有一个查询提示,称为 NOLOCK,可以提高性能。因此,我们修改了用于填充送货地址下拉菜单的查询,使其如下所示。
DECLARE @CustomerID INT ;
SET @CustomerID = 2 ;
SELECT
Street
, Area
, City
, ZipCode
FROM dbo.Addresses a WITH(NOLOCK)
INNER JOIN dbo.Customers c
ON a.AddressID = c.DeliveryAddressID
WHERE CustomerID = @CustomerID ;
一切暂时都很好,但有一天,一份订单被送到错误的地址,我们被要求调查这是如何发生的。
想象以下情景。一名销售人员正在处理 Cooking Schmooking 的订单。与此同时,一名管理员正在与 Cooking Schmooking 团队的另一名成员讨论更新各种细节,包括更改地址。管理员意识到他们输入了错误的地址,并在更新完成之前取消了客户的更新。然后,管理员继续输入正确的地址。我们来看看图 5.1 中的具体事件顺序。
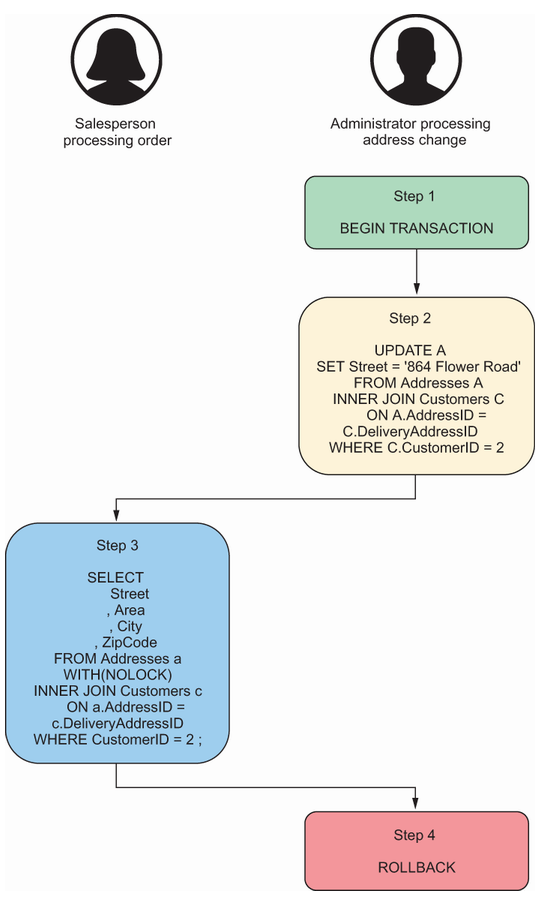
SQL Server 使用锁定来确保一个事务无法读取当前被其他事务修改的数据。通过使用 NOLOCK 查询提示,我们防止了 SELECT 语句获取任何锁。因此,销售人员在事务执行更新时可以从表中读取地址。执行更新的事务随后被回滚。这导致销售人员读取到一个从未真正提交过的送货地址,因此在数据库中根本不存在。
有许多方法可以优化 SQL Server 的性能,而通过使用事务隔离级别来调整锁定,这是影响锁定维护方式的一种选择。我们将在第10章讨论这一点。然而,我始终建议避免在查询中使用 NOLOCK,因为它是一种不透明的优化,通常带来的风险多于收益。
错误16# 使用 SELECT * 作为标准
现在让我们来看一些可能导致性能问题的错误。我们先从这样一个场景开始:我们正在开发一个返回销售信息的过程。我们记不清表中的列或者数据是什么样子;因此,我们运行以下临时查询:
SELECT *
FROM SalesAreas
然后一位同事问我们:“我们是否存储产品的最佳食用日期?”我们不确定,所以我们运行以下临时查询,以便能回答我们的同事:
SELECT *
FROM Products
这两个例子都是 SELECT * 的完全有效的用法。我想讨论的错误是开发者在计划发布和维护的代码中使用 SELECT *。
让我们假设我们的应用程序将对订单的送达时间及其延迟情况进行一些分析。为了满足这个需求,我们需要向前端应用程序返回以下列:
- SalesOrderDate
- SalesOrderDeliveryDueDate
- SalesOrderDeliveryActualDate
然而,我们决定使用 SELECT *,而不是选择这三列特定的列。这样做是错误的有三个原因:性能、代码维护和代码可读性。我们先讨论性能问题。
当我们考虑 SELECT * 时,有两个性能方面需要考虑。第一个是将数据发送到应用层。在这种情况下,我们的应用程序只需要我们发送三列,总共9字节。如果我们向应用程序发送所有列,那么每行的大小将达到每行61字节。这意味着每行额外增加了51字节。想象一下,表中有250万条销售订单。这意味着我们无缘无故地通过网络发送了额外的121MB数据。
现在想象一下,如果我们对一个有多个 NVARCHAR(MAX) 列的表使用相同的技术,每列最多可以存储 2 GB。如果多个用户同时运行相同的查询会怎么样?你可以看到这很容易就会成为一个问题。
我们应该考虑的性能的第二个方面与索引有关。为了解释这个问题,假设确切的要求是返回三个列,并根据 SalesOrderDate 进行过滤。为了以最有效的方式满足此查询,我们可以创建所谓的覆盖索引——也就是包含我们想要返回的所有列的索引。
例如,示例 5.6 创建了一个以 SalesOrderDate 列为基础的索引,但随后包含了 SalesOrderDeliveryDueDate 和 SalesOrderDeliveryActualDate 列。当你使用 INCLUDE 语法时,SQL Server 会在主列上生成索引,然后在叶级包含所包含列的值。这对于覆盖查询特别有用,当你需要在给定列上进行筛选或连接,同时又希望在结果中返回少量其他列时。这是因为它在避免对聚簇索引进行查找以检索其他列的同时,最小化了索引的大小。
CREATE NONCLUSTERED INDEX [OrderDate-Including-DueDate-ActualDate]
ON dbo.SalesOrderHeaders (SalesOrderDate)
INCLUDE(SalesOrderDeliveryDueDate,SalesOrderDeliveryActualDate) ;
不幸的是,如果你使用 SELECT *,那么像这样的索引几乎肯定不会被使用,因为它们不包含你要返回的所有列。当然,也可以包含表中的每一列,但这会使索引非常宽且效率低下。然后,如果我们向表中添加另一列,除非我们记得同时更新索引定义,否则索引将无法工作。
这很好地引出了使用 SELECT * 方法的第二个问题,即代码维护。想象一个作为中间件层的应用程序。它使用类似的查询从 SalesOrderHeaders 表中提取订单日期
SELECT *
FROM dbo.SalesOrderHeaders
WHERE SalesOrderDate = ‘20230616’ ;
然后将数据传入另一实例上的存储过程,该存储过程执行分析。因为我们传递了表中的所有列,所以分析实例上的表类型创建如下:
CREATE TYPE SalesOrdersForAnalysis AS TABLE
(
SalesOrderNumber NCHAR(12) NOT NULL,
SalesOrderDate DATE NOT NULL,
SalesPersonID INT NOT NULL,
SalesAreaID INT NOT NULL,
CustomerID INT NOT NULL,
SalesOrderDeliveryDueDate DATE NOT NULL,
SalesOrderDeliveryActualDate DATE NULL,
CurrierUsedforDelivery NVARCHAR(32) NOT NULL
) ;
存储过程随后以以下方式声明:
CREATE PROCEDURE dbo.AsyncAnalysis
@DatesForAnalysis SalesOrdersForAnalysis READONLY
AS
BEGIN
SELECT *
FROM @DatesForAnalysis ;
–Analysis logic here…
END
在这种情况下,如果我们向 SalesOrderHeaders 表中添加一列,则需要执行以下步骤:
- 删除 AsyncAnalysis 存储过程,因为它依赖于 SalesOrdersForAnalysis 类型。
- 删除 SalesOrderForAnalysis 类型。
- 重新创建 SalesOrderForAnalysis 类型。
- 重新创建 AsyncAnalysis 存储过程。
简而言之,如果我们只使用所需的列,而不是表中的所有列,代码更新会简单得多。在我的职业生涯中,我多次遇到过类似的问题,这会指数级地增加执行简单更改所需的时间。
我们应该避免使用 SELECT * 方法的最后一个原因与代码可读性有关。在第二章中,我们讨论了自文档化代码的好处。使用 SELECT * 会破坏自文档化代码的模式,使你的代码更不透明,也更难以维护,无论是你自己还是其他开发者,因为你想要实现的内容不那么明显。
我建议在需要发布和维护的代码中始终避免使用 SELECT *。它可能对性能产生负面影响,因为会增加网络负载,并且迫使使用效率较低的索引操作来检索数据。在存在下游依赖的情况下,它会使你的代码更难维护。它还会使你的代码更难阅读,并破坏自我文档化的模型。
错误17# 不必要地排序数据
有人要求我们对客户联系人进行一些报告,我们决定如果按电子邮件地址排序,数据可能会更有用。然而,在我们检查之前,让我们为 CustomerContacts 表生成一些数据,使用下列清单中的脚本,该脚本将生成 320 万行数据。
DECLARE @FirstName TABLE (FirstName NVARCHAR(32)) ;
DECLARE @LastName TABLE (LastName NVARCHAR(32)) ;
DECLARE @domain TABLE (Domain NVARCHAR(250)) ;
DECLARE @topleveldomain TABLE (TLD NVARCHAR(6)) ;
DECLARE @email TABLE (Email NVARCHAR(256)) ;
INSERT INTO @FirstName
VALUES
(‘Rachel’),
(‘Seth’),
(‘Tony’),
(‘Angel’),
(‘Isabell’),
(‘Robert’),
(‘Adelaide’),
(‘Jessie’),
(‘Paxton’),
(‘London’),
(‘Jadyn’),
(‘Corey’),
(‘Maximo’),
(‘Johan’),
(‘Mariah’),
(‘Raven’),
(‘Hamza’),
(‘Cristofer’),
(‘Molly’),
(‘Malcolm’) ;
INSERT INTO @LastName
VALUES
(‘Hill’),
(‘Acosta’),
(‘Oconnell’),
(‘Jefferson’),
(‘Cross’),
(‘Patel’),
(‘House’),
(‘Price’),
(‘Morales’),
(‘Reeves’),
(‘Rice’),
(‘Drake’),
(‘Briggs’),
(‘Henry’),
(‘Aguilar’),
(‘Holloway’),
(‘Burnett’),
(‘Aguilar’),
(‘Simon’),
(‘Barry’) ;
INSERT INTO @domain
SELECT
CONCAT(FirstName, LastName)
FROM @FirstName
CROSS JOIN @LastName ;
INSERT INTO @topleveldomain
VALUES
(‘.net’),
(‘.com’),
(‘.co.uk’),
(‘.eu’),
(‘.ru’),
(‘.edu’),
(‘.gov’),
(‘.ninja’),
(‘.io’),
(‘.co’),
(‘.ai’),
(‘.ca’),
(‘.me’),
(‘.de’),
(‘.fr’),
(‘.ac’),
(‘.am’),
(‘.ax’),
(‘.ba’),
(‘.ch’) ;
INSERT INTO @email
SELECT
CONCAT(Domain, TLD)
FROM @domain
CROSS JOIN @topleveldomain ;
INSERT INTO dbo.CustomerContacts(CustomerContactFirstName, CustomerContactLastName, CustomerContactEmail)
SELECT
FirstName
, LastName
FROM @FirstName
CROSS JOIN @LastName
CROSS JOIN @email ;
既然我们已经有了一些数据,让我们遵循我们的简报并编写一个查询,该查询从 CustomerContacts 表中返回 CustomerContactFirstName、CustomerContactLastName 和 CustomerContactEmail 列。在运行此查询之前,以下清单中的脚本将运行命令 SET STATISTICS TIME ON,该命令将在 SSMS 的消息窗口中返回执行时间统计信息。
SET STATISTICS TIME ON ;
SELECT
CustomerContactFirstName
, CustomerContactLastName
, CustomerContactEmail
FROM dbo.CustomerContacts ;
在我的测试平台上,该查询运行花费了 20,679 毫秒。所以现在让我们再试一次,但这次我们将按 CustomerContactEmailAddress 对数据进行排序,如下清单所示。
SET STATISTICS TIME ON ;
SELECT
CustomerContactFirstName
, CustomerContactLastName
, CustomerContactEmail
FROM dbo.CustomerContacts
ORDER BY CustomerContactEmail ;
提示 如果你在跟随进行性能测量,重要的是要注意,你的结果可能会因硬件性能以及可能正在运行的其他进程而有所不同。我还建议不要在测试性能的同时捕获执行计划,因为这会影响时间收集的结果。
在同一个测试平台上,这个查询执行花费了27,415毫秒。这比该查询的无序版本慢了25%。原因是关系型数据库建立在一种被称为集合论的数学分支上,在集合论中,我们考虑集合(set),即一组不同的对象,以及袋(bag,或多重集合multiset),即可能包含重复对象的对象集合。在这两种数学概念中,结果的顺序并不重要。因此,对数据进行排序不是基于集合的操作,而只是呈现操作。因此,只有在确实需要时才应对数据进行排序。
如果我们查看执行计划,即查询优化器决定执行以满足查询的步骤或操作符,我们可以看到在排序操作的相对成本中有所体现。你可以通过多种方式访问执行计划,包括通过查询存储(我们将在第10章讨论)或者元数据(我们也将在第10章讨论),或者只需在 SQL Server Management Studio 的工具栏上点击“包括实际执行计划”按钮,然后再执行查询。
清单5.9中的查询生成的执行计划如图5.2所示。您会注意到排序操作占查询估计成本的91%。
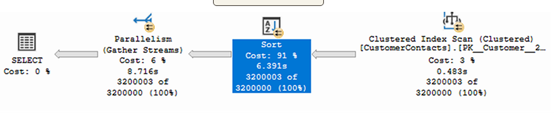
如果出现必须为了展示原因对数据进行排序的情况,那么使用索引可以提供帮助。对于此查询,覆盖查询的理想索引是以 CustomerContactEmail 作为索引键构建,并在叶级包含 CustomerContactFirstName 和 CustomerContactLastName 列。这个索引可以使用清单 5.10 中的命令创建,它按照 CustomerContactEmail 列排序,因此不需要进行排序操作。由于其他所需的列已包含在叶级,因此甚至不需要执行到聚集索引的查找操作。
CREATE NONCLUSTERED INDEX
[NI-CustomerContactEmail-Include-FirstName-LastName]
ON dbo.CustomerContacts(CustomerContactEmail)
INCLUDE(CustomerContactFirstName, CustomerContactLastName) ;
既然我们有了覆盖索引,让我们再次运行列表 5.9 中的查询,看看这对执行计划(如图 5.3 所示)以及执行时间有什么影响。你可以看到,这一次,优化器选择执行非聚集索引扫描,在我的测试环境中,该查询执行耗时 20,904 毫秒,大致与原始未排序查询相同。
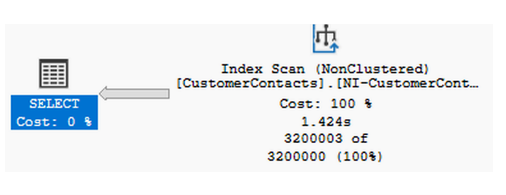
虽然创建索引对于这个特定查询效果很好,但我们需要记住,没有任何事情是免费的。尽管索引已经解决了按电子邮件地址排序的数据查询的性能问题,但索引的存在会降低对表进行 INSERT、UPDATE 和 DELETE 操作的性能,因为 SQL Server 还需要更新非聚集索引。
因此,除非绝对必要,否则最好避免对数据进行排序,因为性能会下降。如果出于展示原因确实需要对数据进行排序,请考虑您的索引策略,但请记住,这会影响对表的写操作性能。
错误18# 无正当理由使用 DISTINCT
我们被要求返回一个唯一供应商的列表。我见过经验较少的开发者使用 DISTINCT 关键字,只是为了确保结果是唯一的。为了研究这一点,我们可以使用清单 5.11 中的任一查询来得到相同的结果。因为(除非我们的数据质量存在严重问题)同一供应商不会在我们的表中被列出两次,所以使用 DISTINCT 关键字是多余的。
SELECT SupplierName
FROM dbo.Suppliers ;
SELECT DISTINCT SupplierName
FROM dbo.Suppliers ;
即使我们不需要 DISTINCT 关键字,使用它会有任何区别吗?为了解答这个问题,让我们看看图 5.4 中的执行计划。如果两个查询的成本相同,那么它们各自相对于批处理的查询成本将为 50%。然而,在这种情况下,你可以看到使用 DISTINCT 关键字的查询的相对成本为 82%,这意味着它效率低得多。你可以在 Distinct Sort 操作符中看到这一点。
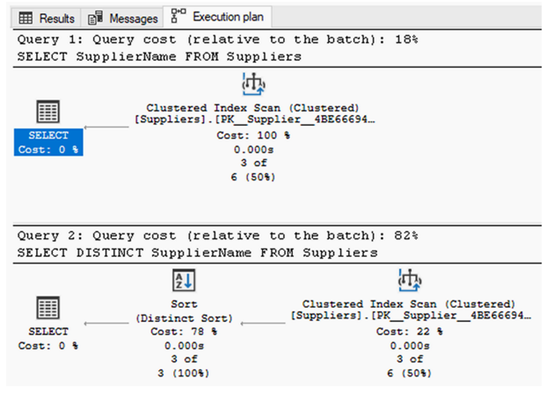
有些情况下,我们可能必须让结果唯一化。例如,设想我们被要求返回一个 MagicChoc 在 2023 年 6 月购买大头链轮的供应商的唯一列表。我们可以使用以下列表中的查询返回供应商列表。
SELECT DISTINCT s.SupplierName
FROM dbo.Suppliers s
INNER JOIN dbo.PurchaseOrderHeaders poh
ON poh.SupplierID = s.SupplierID
INNER JOIN dbo.PurchaseOrderDetails pod
ON pod.PurchaseOrderNumber = poh.PurchaseOrderNumber
WHERE MONTH(poh.PurchaseOrderDate) = 6
AND YEAR(poh.PurchaseOrderDate) = 2023
AND pod.ProductID = 4 ;
问题是,由于在此期间我们从未知工程公司购买了两次该物品,该查询会为供应商返回两个结果。当然,我们可以使用 DISTINCT 关键字,但我们知道这会降低性能。还有其他选择吗?
列表 5.13 中的三个查询在功能上都是等效的。第一个查询使用 DISTINCT 关键字来去重结果,第二个使用 GROUP BY 子句,第三个使用 ROW_NUMBER() 窗口函数。
SELECT DISTINCT s.SupplierName
FROM dbo.Suppliers s
INNER JOIN dbo.PurchaseOrderHeaders poh
ON poh.SupplierID = s.SupplierID
INNER JOIN dbo.PurchaseOrderDetails pod
ON pod.PurchaseOrderNumber = poh.PurchaseOrderNumber
WHERE MONTH(poh.PurchaseOrderDate) = 6
AND YEAR(poh.PurchaseOrderDate) = 2023
AND pod.ProductID = 4 ;
SELECT s.SupplierName
FROM dbo.Suppliers s
INNER JOIN dbo.PurchaseOrderHeaders poh
ON poh.SupplierID = s.SupplierID
INNER JOIN dbo.PurchaseOrderDetails pod
ON pod.PurchaseOrderNumber = poh.PurchaseOrderNumber
WHERE MONTH(poh.PurchaseOrderDate) = 6
AND YEAR(poh.PurchaseOrderDate) = 2023
AND pod.ProductID = 4
GROUP BY s.SupplierName ;
SELECT SupplierName FROM (
SELECT s.SupplierName, ROW_NUMBER() OVER(ORDER BY s.SupplierName) AS rn
FROM dbo.Suppliers s
INNER JOIN dbo.PurchaseOrderHeaders poh
ON poh.SupplierID = s.SupplierID
INNER JOIN dbo.PurchaseOrderDetails pod
ON pod.PurchaseOrderNumber = poh.PurchaseOrderNumber
WHERE MONTH(poh.PurchaseOrderDate) = 6
AND YEAR(poh.PurchaseOrderDate) = 2023
AND pod.ProductID = 4
) a WHERE rn = 1 ;
在我们的具体情况下,因为涉及的行数非常少,并且我的测试环境没有负载,所以三者之间没有性能差异,并且带有 DISTINCT 和 GROUP BY 的版本都生成了相同的执行计划。
然而,在生产环境中,对于复杂的查询和大量数据,你可能会发现你有三种完全不同的执行计划,其中一些明显比其他的更高效。因此,如果你发现使用 DISTINCT 关键字存在性能问题,值得尝试其他两种方法,看看是否能够提高性能。
提示 我可以通过向表中加载更多数据,使 ROW_NUMBER() 查询的性能超过前面示例中的 DISTINCT 和 GROUP BY 查询。然而,本示例展示了基于真实数据进行性能测试的重要性。我们将在第7章进一步探讨这一点。
我们绝不应该单纯为了使用 DISTINCT 而使用它。然而,如果确实有必要对查询结果去重,并且在使用 DISTINCT 时遇到性能问题,那么可以探索其他方法来提高性能。如果 DISTINCT 确实是必需的,并且没有观察到性能问题,那么我建议坚持使用这种方法,因为在三种选项中它是最透明的。你正在做的事情一目了然,这有助于使代码具备自我说明性。
提示 真正需要使用 DISTINCT 可能是由于数据库架构存在潜在问题。有关更多详细信息,请参见第 4 章。
错误19# 不必要地使用 UNION
就像不必要地对数据进行排序和不必要地删除重复一样,刚接触 SQL Server 的开发者在使用 UNION 子句时也会犯类似的错误。联合是一种水平连接两个结果集的方法,而生成这种联合有两种不同的方式。具体来说,你可以使用 UNION 子句或 UNION ALL 子句。
UNION 和 UNION ALL 之间的区别在于 UNION ALL 会返回两个查询的所有结果。然而,UNION 会去除重复的结果。例如,假设我们被要求从 CustomerContacts 表和 SupplierContacts 表中编制 MagicChoc 的联系人列表。列表 5.14 中的第一个查询使用 UNION 创建一个不重复的联系人列表。第二个查询使用 UNION ALL 创建一个可能包含重复项的列表。
提示:还有额外的水平连接操作符,称为 INTERSECT 和 EXCEPT。INTERSECT 将返回查询 1 的结果中也出现在查询 2 结果中的部分。EXCEPT 将返回查询 1 中未出现在查询 2 的结果。
SELECT SupplierContactFirstName, SupplierContactLastName
FROM dbo.SupplierContacts
UNION
SELECT CustomerContactFirstName, CustomerContactLastName
FROM dbo.CustomerContacts ;
SELECT SupplierContactFirstName, SupplierContactLastName
FROM dbo.SupplierContacts
UNION ALL
SELECT CustomerContactFirstName, CustomerContactLastName
FROM dbo.CustomerContacts ;
我们可以从图5.5中的执行计划看到,去重列表的成本显著更高,所以值得检查这一需求。我们真的需要去重列表吗?如果不需要,那么我们就不应该仅仅为了去重而去重。
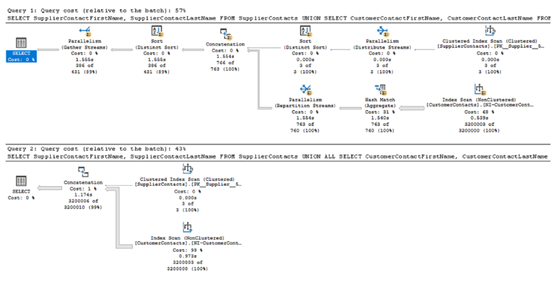
有时我们需要使用 UNION,但我们应该仅在确实有必要的情况下使用它。如果重复项不重要,或者由于业务逻辑不可能出现重复项,那么应使用 UNION ALL。
错误20# 使用游标
MagicChoc 的采购主管希望我们制作一份报告,显示我们按每个产品类别分组的库存产品数量。然而,我们必须以横向格式制作报告,而不是纵向格式,其中列名为产品类别,单行详细说明每个类别的库存产品数量。
许多开发人员在这一点上所犯的错误是使用游标。游标是 T-SQL 中用于循环处理一组行的机制,每次处理一行。游标可以用于多种目的,包括数据透视以及生成和执行动态 T-SQL 脚本,例如对每个表运行命令。它们还可以用于在表的任意列中查找值或对数据进行排名。
问题在于,游标是一种极其低效的处理关系数据的方式。每次游标迭代的开销与以独立方式运行命令的开销相同。例如,如果你有一个遍历 100 万行的游标,其开销就等同于对该表执行 100 万条语句。此外,过去 25 年对 T-SQL 的语言增强已经消除了使用游标的任何必要性。我想不出有任何一种情况必须使用游标才能达到预期结果,而且你很可能(至少希望如此)已经制定了禁止使用游标的编码标准。
提示 即使是以前使用游标在数据库中遍历多个对象的DBA,现在也没有理由这样做。我们将在第9章中进一步讨论这个问题。
所以,回到我们的场景,如果我们继续使用游标来生成透视报表,我们可以使用像清单5.15中的脚本。该脚本首先创建一个具有报表最终结构的临时表。然后我们插入一行包含每列为零的占位行。这将为我们提供可以更新的基础。在声明变量时,我们还声明一个游标,以包含我们将迭代的完整结果集。在我们的场景中,这是一个纵向表格格式的产品类别和数量列表。然后我们打开游标,并使用 FETCH 语句拉取第一行。WHILE 循环告诉游标我们要执行的操作——在我们的例子中,是根据游标中的值更新临时表中的相应列。在 WHILE 循环结束时,我们将下一行拉入游标。当 @@FETCH_STATUS = 0 时,WHILE 循环退出。这个系统变量让我们知道没有剩余行可供抓取。最后,在清理临时对象以免占用内存之前,我们只需从临时表中运行一个 SELECT 语句。
CREATE TABLE #Categories (
[Raw Ingredients] INT,
[Machine Parts] INT,
[Misc] INT,
[Confectionary Products] INT,
[Non-confectionary Products] INT
) ;
INSERT INTO #Categories
VALUES (0,0,0,0,0) ;
DECLARE @Category as varchar(32) ;
DECLARE @Stock as varchar(32) ;
DECLARE product_cursor CURSOR FOR
SELECT
pc.ProductCategoryName
, SUM(ISNULL(p.ProductStockLevel,0)) Stock
FROM dbo.ProductCategories pc
INNER JOIN dbo.ProductSubcategories ps
ON pc.ProductCategoryID = ps.ProductCategoryID
LEFT JOIN dbo.Products p
ON ps.ProductSubcategoryID = p.ProductSubcategoryID
GROUP BY ProductCategoryName ;
OPEN product_cursor ;
FETCH NEXT FROM product_cursor INTO @Category, @Stock ;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @Category = ‘Raw Ingredients’
UPDATE #Categories
SET [Raw Ingredients] = [Raw Ingredients] + @Stock
ELSE IF @Category = ‘Machine Parts’
UPDATE #Categories
SET [Machine Parts] = [Machine Parts] + @Stock
ELSE IF @Category = ‘Misc’
UPDATE #Categories
SET [Misc] = [Misc] + @Stock
ELSE IF @Category = ‘Confectionary Products’
UPDATE #Categories
SET [Confectionary Products] = [Confectionary Products] + @Stock
ELSE IF @Category = ‘Non-confectionary Products’
UPDATE #Categories
SET [Non-confectionary Products] = [Non-confectionary Products] + @Stock ;
FETCH NEXT FROM product_cursor INTO @Category, @Stock ;
END
SELECT
[Raw Ingredients]
, [Machine Parts], [Misc]
, [Confectionary Products]
, [Non-confectionary Products]
FROM #Categories ;
CLOSE product_cursor ;
DEALLOCATE product_cursor ;
DROP TABLE #Categories ;
我们可以不使用昂贵的游标,而是使用 PIVOT 操作符。这个操作符会为我们完成繁重的工作,并以基于集合的操作方式执行,这比使用游标要高效得多。
现实世界的例子
大约十年前,我曾在全球最大的广告公司之一工作,该公司使用从搜索引擎和Cookie服务提供商收集的大型数据集。他们让我查看他们在一个ETL作业上遇到的性能问题,该作业对一个大型数据集进行了透视。
他们最初的实现使用了游标。我重写了该过程,使用 PIVOT 语句代替游标。这样做将执行时间从超过 3 小时缩短到了 48 秒!
列表 5.16 中的单个查询实现了与游标相同的结果。外部查询指定了我们希望从查询中返回的列。这里我们可以使用 *,也可以指定列列表。如果我们使用列列表,则无需选择所有透视的列。子查询提取了一个类别和库存数量的扁平列表。最后,PIVOT 操作符通过指定我们希望针对库存列使用的聚合以及我们希望作为透视列的 ProductCategoryName 列中的值来定义最终结果集。
SELECT
[Raw Ingredients]
, [Machine Parts]
, [Misc]
, [Confectionary Products]
, [Non-confectionary Products]
FROM (
SELECT
pc.ProductCategoryName
, ISNULL(p.ProductStockLevel,0) Stock
FROM dbo.ProductCategories pc
INNER JOIN dbo.ProductSubcategories ps
ON pc.ProductCategoryID = ps.ProductCategoryID
LEFT JOIN dbo.Products p
ON ps.ProductSubcategoryID = p.ProductSubcategoryID
) AS WorkingTable
PIVOT
(
SUM(Stock)
FOR ProductCategoryName IN ([Raw Ingredients], [Machine Parts], [Misc], [Confectionary Products], [Non-confectionary Products] )
) AS PivotTable ;
为了演示查询成本的差异,我们可以将 PIVOT 查询复制到与我们的游标操作相同的查询窗口中。如果我们随后查看此语句的执行计划,我们可以看到它仅占整个批处理成本的 9%,这意味着对于基于游标的方法,我们必须执行的语句的总成本估计比使用 PIVOT 操作效率低超过 10 倍。执行计划的相关部分如图 5.6 所示。
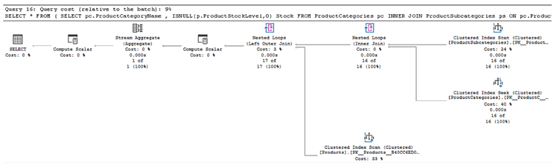
错误21# 在单个事务中删除多行
SQL 开发人员被要求从表中删除旧数据并不罕见。通常,这之后会进行数据库收缩操作,从而回收空间。我们将在第 9 章和第 11 章再次讨论数据库收缩操作。
从表中删除大量数据的最有效方法是使用一个名为 TRUNCATE TABLE 的命令。该命令通过释放数据页来移除表中的数据,同时保持表结构不变。问题在于,截断操作没有 WHERE 子句。它是全有或全无,换句话说,你必须删除每一行。
即使你确实希望删除表中的每一行,表截断也存在其他限制。例如,如果表中的某一列被外键约束或边约束引用,你就无法执行该操作,边约束用于执行语义检查并确保边表的完整性,而边表表示图数据库中的关系。此外,如果表是索引视图中的基础表,参与事务复制或合并复制,或者是系统版本化的临时表(用于跟踪另一张表的完整数据变更历史以允许进行时间点分析的表),也不能使用截断操作。
这些限制常常迫使开发人员使用DELETE语句从表中删除大量行。我在这里看到的错误是,开发人员会尝试在一个事务中删除表中的所有行。例如,考虑一个拥有数百万(甚至数十亿)行的表。
清单 5.17 中的脚本创建了一个表,并使用非常大量的行填充它。它创建的行数会根据数据库中的表和列而有所不同,但在我的测试环境下,它将生成略低于 35 亿行。
警告:此脚本运行将花费较长时间。
CREATE TABLE dbo.VeryLargeTable (
ID BIGINT IDENTITY PRIMARY KEY,
TextCol NVARCHAR(4000)
) ;
DECLARE @LoopCounter INT = 0 ;
WHILE @LoopCounter < 2000
BEGIN
INSERT INTO dbo.VeryLargeTable (TextCol)
SELECT ‘Yet another row in a very, very, very large table. In fact, this table is going to take a very long time to craete, and you will not be able to delete all rows in one go!’
FROM sys.columns c1
CROSS APPLY sys.columns c2 ;
SET @LoopCounter = @LoopCounter + 1 ;
END
让我们尝试使用清单 5.18 中的查询在一个事务中删除这个表中的所有行。请记住,如果我们不启动显式事务,那么每条语句都会在自动提交事务中运行。换句话说,事务的最低粒度是一条语句。
DELETE FROM dbo.VeryLargeTable ;
该语句将导致一个非常大的事务。在事务打开期间,事务日志无法截断自身以释放空间。即使在简单恢复模型中也是如此(我们将在第12章讨论恢复模型)。事实上,事务将变得如此之大,以至于事务日志空间耗尽,查询将回滚,从而导致抛出9002错误,如图5.7所示。

相反,我们需要将 DELETE 操作拆分为多个语句,因此也就是多个事务。假设数据库处于 SIMPLE 恢复模式,这将防止事务日志变满,因为它能够在语句执行之间进行截断。这是极少数我会考虑在生产环境中使用 WHILE 循环的情景之一,而且那也是因为这是一个临时脚本。我会总是避免在打算部署的代码中使用 WHILE 循环,原因与我避免使用游标的原因相同。在清单 5.19 中,我们设置脚本每次删除 250,000 行。你可以根据环境特点调整这个数字以优化性能。
警告:此脚本运行将花费较长时间。
DECLARE @RowCounter BIGINT ;
SET @RowCounter = 1 ;
WHILE @RowCounter > 0
BEGIN
DELETE TOP(250000)
FROM dbo.VeryLargeTable ;
SET @RowCounter = (SELECT COUNT(*) FROM dbo.VeryLargeTable) ;
PRINT @RowCounter ;
END
修改数据的操作,例如 DELETE 操作,在对大型表运行时可能导致事务日志变满。为避免此问题,可以将操作拆分成多个语句并逐一执行。
总结:
- 请记住,NULL 是一个未知值,因此不等于另一个 NULL 值。
- 避免将 NOLOCK 查询提示作为性能优化使用,因为它可能导致意外结果,返回数据库中从未存在过的数据。
- 除即席查询外,避免使用 SELECT *,因为它可能导致性能和代码维护问题,同时这也是自文档化代码的反模式。
- 对数据进行排序是展示特性,而不是基于集合的特性。只有在绝对必要时才排序数据。
- 除非你确实需要,否则不要使结果唯一化。如果 DISTINCT 导致性能问题,可以考虑使用其他技术,如 GROUP BY 或 ROW_NUMBER()。
- UNION 比 UNION ALL 更昂贵,因为它会去除重复项。因此,如果重复项不重要或不可能出现,应使用 UNION ALL 而不是 UNION。
- 应避免使用游标。它们代价很高,并且在现代版本的 SQL Server 中,没有无法通过其他方法执行的操作。
- 从表中在单个事务中删除大量行可能会导致事务日志填满。通过将删除操作拆分为多个批次,可以避免这种情况。



