第四章 数据库设计
本章涵盖了
- SQL Server 中的设计错误以及为什么避免这些错误很重要
- 未能对数据库进行规范化的错误
- 设计和创建键时出现的错误
在本章中,我们将讨论在设计数据库时常见的错误。这些错误可能导致多种挑战,从而造成代码性能不佳等问题。
设计错误是在开发生命周期的最早阶段引入的,此时还没有编写任何代码。为了说明这一点,让我们关注 MagicChoc 公司。该公司认为其流程过于分散,因此委托开发一款新应用程序,该应用程序将把其非互联网销售和采购功能整合到单一界面和单一后台中。为此,MagicChoc 的管理团队表示他们希望存储以下数据项:
- 销售订单日期
- 销售订单号
- 销售人员姓名
- 销售人员邮箱
- 销售区域名称
- 销售区域经理
- 客户公司名称
- 客户联系人姓名
- 客户联系人邮箱
- 客户发票地址
- 客户送货地址
- 销售订单交货截止日期
- 销售订单实际交货日期
- 销售订单项目
- 销售订单数量
- 用于交货的快递
- 产品名称
- 产品库存水平
- 产品下次生产日期
- 产品下次生产数量
- 未完成订单
- 制造ID
- 产品类型名称
- 产品类型描述
- 产品类别名称
- 产品类别描述
- 产品子类别名称
- 产品子类别描述
- 供应商名称
- 供应商联系人姓名
- 供应商联系人邮箱
- 供应商地址
- 采购订单日期
- 采购订单号
- 采购订单项目
- 采购订单数量
在本章中,我们将设计存储这些数据所需的表结构。在此过程中,我们将探讨如何避免常见的设计错误。具体来说,我们将研究如果未能对数据库进行规范化可能出现的问题。然后,我们将研究与不当选择主键相关的性能问题。最后,我们将探讨不创建外键约束的后果。
错误11# 未能标准化
很多次,我问开发人员:“数据库是规范化的吗?”答案总是“是的!”不幸的是,在许多情况下,开发人员在数据库设计方面相对缺乏经验,他们误解了我的问题,以为我是在问“你设计的是联机事务处理(OLTP)数据库,而不是数据仓库吗?”实际上,他们并没有对数据库进行规范化,而只是凭自己的判断来决定数据库模式。
为了设计我们的数据库模式,我们将创建一个实体关系图(ERD),它是一个描述实体的图,实体是数据模型中的对象,以及描述数据对象的属性。ERD还描述了模型中对象之间的关系。
在接下来的章节中,我们将首先探讨设计数据库模式的错误方法,即使用判断方法。在这种方法中,我们仅依靠自己的经验来组织数据。由于每个人的经验不仅水平不同,而且本质上也不同,当我们使用这种无结构的方法时,会出现多种问题。我们将检查一些较为常见的问题,例如非原子值和数据重复。
最后,我们将探讨如何通过使用规范化来设计我们的数据库模式,以避免错误。我们将研究这种结构化的数据库建模方法,这种方法最早由埃德加·科德在20世纪70年代开发,并经受住了时间的考验。这是一系列有条理的步骤,用于消除数据冗余。在使用这种方法时,我们将遵循一套严格的规则,旨在避免数据重复并使模式尽可能高效。我们还将涉及如何使用实体关系图来测试我们的规范化,并了解数据泛化的概念。
依靠判断来设计模式
让我们用我们的判断来设计 MagicChoc 请求的新销售和采购数据库的模式。它希望建模 35 个数据项,所以让我们让事情更简单一些,把它们分成几个部分。让我们从销售订单数据开始——具体来说,是以下数据项:
- 销售订单日期
- 销售订单编号
- 销售人员姓名
- 销售人员邮箱
- 销售区域名称
- 销售区域经理
- 销售订单交付截止日期
- 销售订单实际交付日期
- 销售订单项目
- 销售订单数量
- 交付使用的快递
销售订单编号属性将是唯一的,因此这看起来像是我们实体的一个良好主键候选。棘手的方面是销售订单项与销售订单数量之间的关系。我们注意到存在明显的一对多关系。这是一种实体之间的关系,其中一个实体中的单个记录可以与另一个实体中的多个记录相关联。在这种情况下,任何给定订单可能订购多个产品,因此我们决定将订购的商品拆分到一个不同的实体中。我们还认为,由于我们有存储一般产品详细信息的需求,所以将产品详细信息排除,只关联到产品实体将是合理的,我们将很快设计该实体。
同样地,由于我们假设客户可能会下多个订单,并且我们知道根据需求需要存储客户详细信息,因此我们决定在创建 Orders 表时,应创建一个可以与 Customers 表连接的键。最后,我们注意到没有一个合适的主键候选,因此我们将创建一个人工键。这使我们得到了 ERD 的初步版本,如图 4.1 所示。
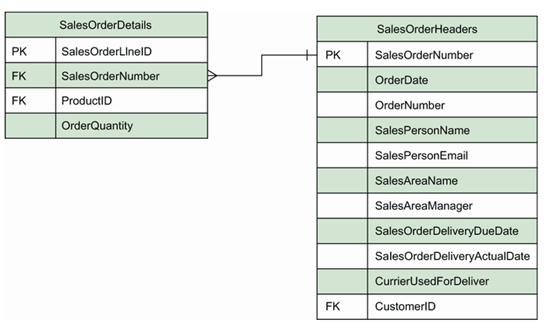
接下来,我们将查看关于产品数据的要求,我们需要存储以下数据:
- 产品名称
- 产品库存水平
- 产品下次生产日期
- 产品下次生产数量
- 代工订单 制造ID
- 产品类型名称
- 产品类型描述
- 产品类别名称
- 产品类别描述
- 产品子类别名称
- 产品子类别描述
我们决定建立一个产品表,由于没有明显的自然键,我们将创建一个人工键,该键将与销售订单明细实体中的 ProductID 属性相链接。我们还注意到产品与产品类别之间可能存在一对多的关系,因此我们决定创建一个单独的产品类别实体,并通过另一个人工键将其与产品实体关联起来。如果我们将这些实体与销售订单实体结合起来,我们将得到图 4.2 所示的 ERD。
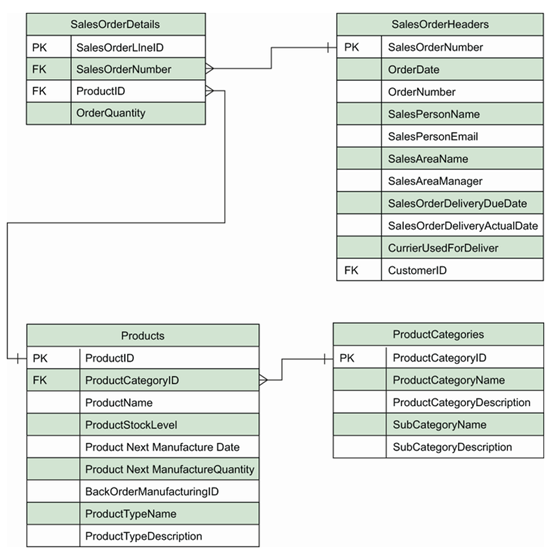
接下来,我们将构建 Customers 实体,我们知道它将具有以下属性:
- 客户公司名称
- 客户联系人姓名
- 客户联系人邮箱
- 客户发票地址
- 客户收货地址
为了避免出现宽而稀疏的表,我们决定将地址移到不同的实体中。我们还意识到,我们可以有一个单一的地址实体,同时关联客户发票地址和客户送货地址。如果发票地址与送货地址相同,这可以避免数据重复。我们通过为每种地址类型添加标志来实现这一点。我们将为这两个实体创建人工键。将这些实体附加到我们现有的设计中,会得到图 4.3 所示的 ERD。
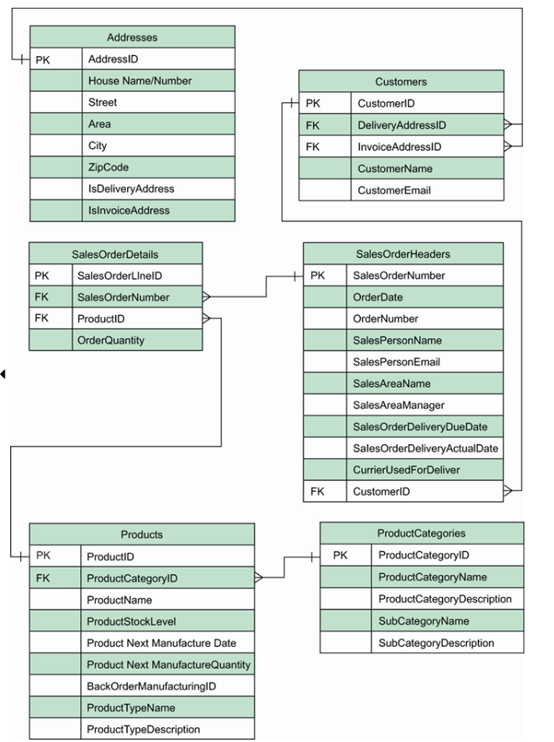
最后,让我们为供应商和采购订单添加实体。我们需要为这些实体建模的数据属性是
- 供应商名称
- 供应商联系人姓名
- 供应商联系人邮箱
- 供应商地址
- 采购订单日期
- 采购订单编号
- 采购订单项目
- 采购订单数量
我们决定以类似于我们建模客户和销售订单的方式来建模供应商和采购订单。我们将拥有一个供应商实体,该实体将链接到我们现有的地址实体以存储供应商地址。我们将采购订单拆分为两个实体:一个用于采购订单头,另一个用于采购订单明细。同样,这是为了允许我们在同一订单中订购多个项目,而无需为每个项目重复订单数据。我们决定为供应商和采购订单明细创建一个人工键,但在采购订单头实体中使用采购订单号作为自然键。
如果我们将这些剩余的实体添加到我们现有的设计中,那么我们将得到图4.4所示的ERD。所以,在那里,我们有了一个完整的数据库模式设计。这并不难,是吗?但是使用这种方法有什么问题呢?问题在于,这个模式设计中存在多个错误,这些错误会使我们的数据库非常难以使用,并可能导致性能问题。在下一节中,我们将讨论一些错误及其后果。
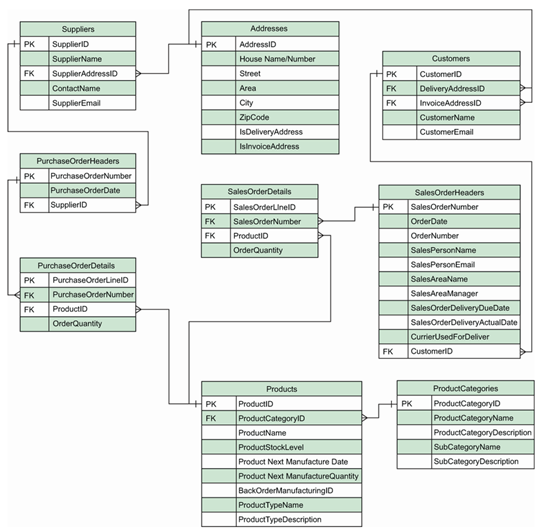
我们的数据库模式存在问题
乍一看,我们的数据库架构可能看起来相当合理,但如果仔细观察我们的一些设计选择,就会看到问题会出现在何处。让我们先看看客户和供应商姓名,这是最容易发现的问题之一。
供应商实体的 SupplierName 属性和客户实体的 CustomerName 属性都将存储姓名。这可能会引发各种问题。假设我们的销售应用程序具有邮件合并功能,并且我们希望以“亲爱的 Robert,”开头给客户写信,其中 Robert 是客户的名字。要检索这个名字,我们需要运行类似以下的查询
SELECT SUBSTRING(CustomerName, 0, CHARINDEX(‘ ‘, CustomerName, 1))
FROM Customers ;
这不仅使我们的代码更复杂,阅读和编写起来更加困难,而且效率也比直接从表中选择 FirstName 列低。因此,我们应始终确保我们的值是原子的。原子值是指无法进一步拆分但仍保留其含义的值。例如,名字 Peter A. Carter 可以拆分为三个原子值——名字、中间名首字母和姓氏。认为它可以拆分为 12 个字符的论点是不成立的,因为这些值将没有上下文意义。
提示:这个规则的例外情况是,当在规范化一个模式之后,你有意决定对数据进行反规范化。例如,你可能决定将地址数据存储为 JSON,如第 3 章所讨论的那样。避免规范化的其他原因包括我们在处理分析数据或创建暂存表时。
另一个问题出现在我们的 ProductCategories 实体中。该实体既包含产品类别,也包含子类别。但一个类别中可能有多个子类别。这意味着我们将不得不为每个产品子类别重复 ProductCategoryName 和 ProductCategoryDescription。数据重复会浪费空间,这会使表变大,从而读取速度变慢,同时占用更多内存,并使索引操作效率降低。然而,更大的问题在于插入和更新操作。由于需要在多行上更新产品类别详情,这些操作会变得效率更低。我们本可以通过将数据拆分为更多实体并使用主键/外键关系将它们连接起来来避免这个问题。
我们已决定在 SalesOrderHeader 实体中存储 SalesAreaName。这意味着名称将被多次重复,因为它可能适用于多行。这也意味着我们的销售区域经理必须为每条记录重复。再次强调,如果销售区域的详细信息被拆分到不同的实体中,并通过主键/外键关系重新连接,那么就可以避免这种情况。
我们在 SupplierContactName 上也有类似的问题。这个值不仅不是原子的,而且根据业务规则,我们也可能会重复数据。如果我们的两个供应商属于同一个人怎么办?另外,如果将来我们需要存储额外的联系信息,比如联系人的专用电话号码呢?这只会加剧问题,同时也会使我们的供应商实体变得非常宽。
这给我们留下了许多问题。我们本可以如何避免这些设计问题?我们的设计还有其他问题吗?我们甚至如何在不构建整个架构并填充数据的情况下测试它,以找出问题?
所有这些问题的答案是使用规范化的过程来设计我们的数据模式。我们将在下一节中讨论如何使用这一过程。
注意,如果没有对业务数据和业务规则的理解,我们无法发现的另一个问题是销售订单号的格式将是 ABC1234D-E12。这会给我们带来一个非常宽的主键。本章的后面部分将讨论这个主题。
使用规范化设计数据库模式
正如本章前面提到的,规范化是一种正式的数据建模过程,最早由埃德加·科德(Edgar Codd)在20世纪70年代创建,并经受住了时间的考验。该过程中有10个规范形式或步骤,这些步骤随着时间的推移被逐渐添加到方法论中。最近添加的基本元组规范形式(Essential Tuple Normal Form)是在2012年才加入的。具体来说,这些规范形式是
- 第一范式 (1NF)
- 第二范式 (2NF)
- 第三范式 (3NF)
- 基本键范式 (EKNF)
- 博伊斯-科得范式 (BCNF 或5NF)
- 第四范式 (4NF)
- 基本元组范式 (ETNF)
- 第五范式 (5NF)
- 域键范式 (DKNF)
- 第六范式 (6NF)
在绝大多数情况下,没有必要超过第三范式(3NF)。同样重要的是,如果我们对模式进行过度规范化,也可能会产生其他问题。因此,本章将重点放在将我们的数据模式建模为第三范式(3NF)。
为了将数据建模为第一范式(1NF),我们将确保所有属性都是原子的且具有唯一名称,并且它们的顺序无关紧要。我们还将确保重复的属性组被移动到不同的实体中,并且行的顺序不重要。
当我们将数据建模为第二范式(2NF)时,我们将确保所有属性都依赖于构成复合主键的所有属性。如果不依赖,我们将把它们移到一个新的实体中。最后,当我们将数据建模为第三范式(3NF)时,我们将确保属性不依赖于当前不属于主键的属性。如果它们依赖,那么这同样表明它们应该被移到一个新的实体中。
在我们开始之前,我们将把属性分为三大类数据类型:销售、采购以及与销售和采购相关的产品。这为我们提供了未规范化形式的初始数据,如下所示:
- 销售
- 销售订单日期
- 销售订单号
- 销售人员姓名
- 销售人员电子邮件
- 销售区域名称
- 销售区域经理
- 客户公司名称
- 客户联系人姓名
- 客户联系人电子邮件
- 客户发票地址
- 客户送货地址
- 销售订单交货截止日期
- 销售订单实际交货日期
- 销售订单项目
- 销售订单数量
- 用于交货的快递
- 采购供应商名称
- 供应商联系人姓名
- 供应商联系人电子邮件
- 供应商地址
- 采购订单日期
- 采购订单号
- 采购订单项目
- 采购订单数量
- 产品
- 产品名称
- 产品库存水平
- 产品下一次生产日期
- 产品下一次生产数量
- 返订单 制造ID
- 产品类型名称
- 产品类型描述
- 产品类别名称
- 产品类别描述
- 产品子类别名称
- 产品子类别描述
第一范式
为了使一个关系处于第一范式,它必须满足以下规则:
- 所有属性都是原子的。
- 每个属性都有唯一的名称。属性的顺序无关紧要。
- 重复组被移除。
- 所有行必须是唯一的(必须有一个键)。
在我们的例子中,每个属性已经有了唯一的名称,并且属性的顺序无关紧要,所以我们有一个良好的开端。然而,我们确实需要将一些属性分解为原子属性。我们还需要检查数据中是否存在重复组,即重复的列组。我们还需要找到候选键,也就是形成最小超键的一组列。超键是能够唯一标识每一行的键,如果移除超键中的任何一列就无法唯一标识每一行,则该键是最小的。
首先,让我们确定将在每个关系中用于唯一标识行的键。销售数据可以通过销售订单号唯一标识。因此,没有必要使用由多个属性组成的组合键。如果一个键由单个属性组成,那么它被称为主属性。
采购数据可以通过采购订单号唯一识别。因此,它本身就是一个超级键,我们也可以再次将其作为单个属性候选键使用。
仅凭产品名称无法识别产品数据,因为从供应商订购的某些零件与销售给客户的产品同名。因此,我们需要同时使用产品名称和产品类型名称来唯一识别任意给定的记录,这两个属性因此将构成我们的候选键。
这个过程已经帮助我们发现了数据模型的第一个问题。我们的销售数据和采购数据都包含产品名称(分别是销售订单项和采购订单项)。问题是我们发现需要同时使用产品名称和产品类别名称来唯一标识一个产品。因此,让我们将产品类别名称添加到每个这些实体中。我们还应该为每个与产品关系连接的关系添加关系。在此过程中,让我们将销售订单项属性和采购订单项属性的名称更改为产品名称,以使关系更加清晰。
接下来,我们应该寻找非原子值。我们未规范化数据中的非原子值,需要将其拆分的是
- 销售人员姓名——我们将其拆分为销售人员名字和销售人员姓氏。
- 销售区域经理——我们将其拆分为销售区域经理名字和销售区域经理姓氏。
- 客户联系人姓名——我们将其拆分为客户联系人名字和客户联系人姓氏。
- 客户发票地址——我们将其分解为以下属性:
- 发票地址街道
- 发票地址区域
- 发票地址城市
- 发票地址邮政编码
- 发票地址国家
- 客户送货地址——我们将其分解为以下属性:
- 送货地址街道
- 送货地址地区
- 送货地址城市
- 送货地址邮政编码
- 送货地址国家
- 产品名称和产品类型名称(在销售关系中)——这是一个棘手的问题。这个属性将存储单个订单中订购的多个产品,但我们无法真正将其分解为多个属性,因为单个订单中可以放置的商品数量没有定义。因此,我们将把它分离到一个不同的关系中,并携带我们选定为主键的销售订单号,以便新的关系可以连接回原始关系。我们还将带上销售订单数量(我们将其简化为数量),否则也会遇到同样的问题。
- 供应商联系人姓名——我们将其拆分为供应商联系人名和供应商联系人姓。
- 供应商地址——我们将其分解为以下属性:
- 供应商地址街道
- 供应商地址区域
- 供应商地址城市
- 供应商地址邮政编码
- 供应商地址国家
- 产品名称和产品类型名称(在采购关系中)——与销售关系一样,我们需要将这些属性移到一个新的关系中,并携带采购订单号,以便我们可以连接这些实体。同样,我们将引入采购订单数量属性,并将其缩短为数量。
最后,我们需要查找重复的组。你可能已经从项目符号列表中注意到,构成发票地址的属性与构成销售关系中的送货地址的属性完全相同。因此,我们应该将这两个地址移到一个新的关系中,我们将其称为地址。我们将在新关系中添加一个附加属性,其候选键将是街道和邮政编码。然后,我们将在销售关系中将这些属性带回两次,一次用于发票地址,另一次用于送货地址。
第二范式
为了使关系处于第二范式(2NF),关系必须遵守以下规则:
- 关系必须处于第一范式(1NF)。
- 所有属性必须依赖于整个关键字。
好的,所以我们知道我们的关系已经在第一范式(1NF)中,但我们如何确保对整个关键字的函数依赖呢?首先值得注意的是,这条规则只适用于具有复合键的关系。按照定义,如果一个自然键由一个主属性组成,那么所有其他属性都必须依赖于它。
在我们的例子中,我们只有一个属性不依赖于复合键中的所有属性。这个属性是产品关系中的产品类型描述属性。该属性仅依赖于产品类型名称属性。因此,让我们将产品类型名称和产品类型描述属性提取到一个单独的关系中,其中产品类型名称成为主属性。我们还将把产品类型名称作为外键重新放回到产品关系中。
第三范式
最后,我们需要将我们的关系转换为第三范式(3NF)。
- 3NF的规则指出,关系必须处于第二范式(2NF)。
- 所有属性必须非传递依赖于关键字。
我们的关系已经处于第二范式(2NF),这很好。但我们需要确保非传递依赖,这意味着属性不能依赖关系中的任何非主属性。
如果我们查看我们的数据,我们会发现有相当多的属性示例,其依赖于非主属性的程度比依赖候选键的程度还要大。第一个例子出现在销售关系中:销售人员的名字和姓氏。合理地预期,销售人员的电子邮件是唯一的,这意味着它可以用于识别这些属性的每一个唯一组合。因此,我们将把这三个属性全部移动到一个新的销售人员关系中,其中销售人员电子邮件是主属性,并将销售人员电子邮件属性作为外键带回到销售关系中。
销售关系还包含销售区域经理的名字和姓氏。这两个属性都可以通过销售区域名称属性唯一标识。因此,我们将它们引入销售区域关系中,并保留销售区域名称作为外键。
客户联系人名字、客户联系人姓氏、客户电子邮件,以及送货地址键和发票地址键,都可以通过客户公司名称属性唯一标识。因此,我们将把这些移到一个客户关系表中,并通过客户公司名称键将其重新连接回去。然而,这是一个有趣的例子,因为一旦我们创建了这个新关系表,您可能会注意到我们现在也可以通过客户电子邮件来识别客户联系人名字和客户联系人姓氏。因此,我们应该将这些属性移到另一个关系表中,称为客户联系人,并使用客户联系人电子邮件作为键将其重新连接到客户关系表。
以类似的方式,当我们查看采购关系时,我们会发现供应商联系人名字、供应商联系人姓氏和供应商地址键都可以通过供应商名称唯一标识,因此应该移到供应商关系中。但是,供应商联系人名字、供应商联系人姓氏和供应商联系人电子邮件应当移到供应商联系人关系中,以供应商联系人电子邮件作为主键。
TIP 供应商联系人、客户联系人和销售人员将是概括的良好候选对象。如果我们想概括这些数据,我们可以创建一个单一的联系人实体,该实体将包含所有联系人类型。为了使过滤更容易,我们可以在实体中创建一个联系人类型属性。然后,该实体将与供应商、客户和销售实体连接。
在 Products 关系中,产品类别名称、产品类别描述以及产品子类别描述都可以通过产品子类别名称唯一标识,因此我们将把这些属性下移到 Product Subcategories 关系中。此外,我们还应该将产品类别描述下移到 Product Categories 关系中,该关系以产品类别名称属性为主键。
最后,ProductNextManufactureDate 和 ProductNextManufactureQuantity 属性可以通过 BackOrderManufacturingID 属性来识别,因此我们将把这些属性移到一个新的未完成订单(Back Orders)关系中。
我们现在应该花时间整理一些事情。首先是我们的关系名称。经过建模后,Sales 对于其所代表的数据不再是有意义的名称。让我们将其更改为 Sales Order Header。此外,Purchasing 也不再充分代表其属性,因此我们应将其更改为 Purchase Order Header。
宽主键是不好的。我这里不会过多细节说明,因为我们会在下一个错误中讨论这个,但目前我们所有的键都是自然键,即具有业务含义的键。对于复合键,我们应将其替换为人工键,即存储没有业务含义的任意值的键——通常是递增的数字。我们还应将基于文本的键替换为人工键。同样,这会使键更窄。
最后,我们应该从关系和属性名称中移除所有空格。这是为了在创建数据库表和列时让它们更适合数据库使用。如果我们的关系和属性名称中包含任何特殊字符或保留字(即 SQL Server 使用的词,例如 “SELECT” 或 “table”),我们也应该考虑更改它们。如果我们没有采取这一步,那么在 SQL Server 中引用这些对象时就必须使用限定标识符。这意味着要将名称用方括号括起来。例如,SELECT MyColumn FROM MyTable 会变成 SELECT [MyColumn] FROM [MyTable]。使用限定标识符被认为是不好的做法,因为它会让代码显得杂乱,并且如果我们需要使用它们,就说明我们没有遵循标识符命名的标准规则和惯例。
错误12# 使用宽主键
如前一节所述,我们已选择 SalesOrderNumber 作为 SalesOrderHeaders 表的主键,但订单编号的格式为 ABC1234D-E12。这意味着我们的列的数据类型为 NCHAR(12)。这表示每行该列占用 24 字节的空间,而 INT 类型仅需 4 字节的空间。即使是 BIGINT 也仅占用 8 字节的空间。
我们在第3章中讨论了使用尽可能小的数据类型的好处,但这些数据中有字母。根据业务规则,我们可能能够使用 CHAR(12),但即便如此,每行也会消耗12字节的存储——那么我们能做些什么呢?而它作为主键列有什么意义呢?
为了回答这些问题,让我们思考一下 SalesOrderHeaders 表的索引策略。主键列默认情况下将具有聚集索引。聚集索引将数据组织成 B 树。这是一种由多层索引页构成的结构,这些索引页提供指向结构中较低层索引页的指针。总是有一级根层,由一个单页组成,称为索引分配地图(IAM)。根据表的大小,可能还会有零个或多个中间层。聚集索引的底层(叶子)是表的实际数据页。
由于索引中的数据是有序的,因此可以通过称为聚集索引查找的操作非常快速地找到记录。此操作会遍历索引的各个层级以定位记录。这与聚集索引扫描不同,聚集索引扫描是一种必须搜索索引叶级的每一页,直到找到所需记录的操作。这些操作,以及B树结构的示例,如图4.6所示。你会注意到,每当搜索单行时,查找操作读取的最大页数等于B树的层数。然而,索引扫描读取的最大页数等于组成索引叶级的数据页数,因此也等于表的数据页数。如果操作可以返回多行记录,则使用查找操作来找到读取叶级的起点。
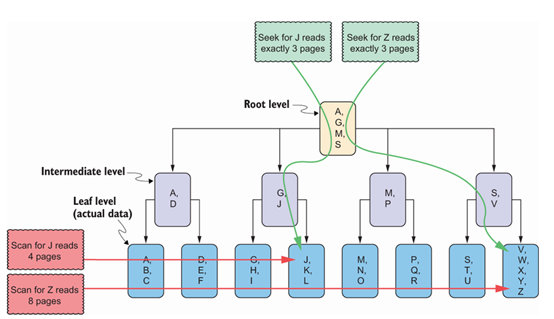
提示 因为聚集索引会对表的数据页进行排序,所以一个表上只能有一个聚集索引。没有聚集索引的表称为堆。在堆中,记录按无特定顺序存储。堆通常用于如暂存表等目的,这些表中有大量临时数据插入,顺序无关紧要,这可以优化性能。
业务部门告诉我们,他们经常通过筛选订单日期来查询销售订单。因此,我们希望通过在 SalesOrderDate 列上创建非聚集索引来优化这些查询。非聚集索引创建了一个与聚集索引非常相似的 B 树结构。不同之处在于,索引的叶子层不包含实际数据,而是包含指向聚集索引或堆中数据的指针。由于叶子层只是指针,这意味着实际数据不会被排序。因此,我们可以在单个表上创建多个非聚集索引。指向聚集索引的指针由聚集索引键组成。这意味着宽的聚集键会被复制到所有非聚集索引中。
注意 如果非聚集索引有 INCLUDE 列,则这些列的实际数据值将与指向索引或堆的指针一起存储在索引中。
此外,业务部门告诉我们,销售订单查询通常会包括销售区域信息和客户信息。这些数据存储在不同的表中,因此我们还希望在 SalesAreaID 和 CustomerID 列上创建非聚集索引,这些列是这些表的外键。通过在外键上创建非聚集索引,键的排序方式与我们要连接的表中的主键对应列相同。这可以让连接操作更加高效。
为了了解拥有宽主键的后果,让我们先向相关表中添加一些数据。清单 4.2 中的脚本向相关表中添加了一小部分数据。然后,它在 SalesOrderHeaders 表上创建了非聚集索引。无需创建聚集索引,因为当我们在表上创建主键时,它会自动创建。
INSERT INTO dbo.SalesPersons (SalesPersonFirstName, SalesPersonLastName, SalesPersonEmail)
VALUES
(‘Robin’, ‘Wells’, ‘[email protected]’),
(‘Jack’, ‘Jones’, ‘[email protected]’),
(‘Jane’, ‘Smith’, ‘[email protected]’) ;
INSERT INTO dbo.SalesAreas (SalesAreaName, SalesAreaManagerFirstName, SalesAreaManagerLastName)
VALUES
(‘US’, ‘Lucy’, ‘Sykes’),
(‘Euro’, ‘Ashwin’, ‘Kumar’),
(‘APAC’, ‘Emma’, ‘Roberts’) ;
INSERT INTO dbo.Addresses (Street, Area, City, ZipCode)
VALUES
(‘744 Saxon Rd’, NULL, ‘Crawfordsville’, ‘47933’),
(‘267 Old York Ave.’, NULL, ‘Reno’, ‘89523’),
(‘923 Taylor Ave.’, NULL, ‘Charlotte’, ‘28205’),
(‘942 Cactus Street’, NULL, ‘Albany’, ‘12203’),
(’32 Selby Drive’, NULL, ‘Pittsfield’, ‘01201’),
(’65 New Street’, ‘Landford’, ‘Salisbury’, ‘SP5 2QP’) ;
INSERT INTO dbo.CustomerContacts (CustomerContactFirstName, CustomerContactLastName, CustomerContactEmail)
VALUES
(‘Ralphie’, ‘Buchanan’, ‘[email protected]’),
(‘Bettie’, ‘Peters’, ‘[email protected]’),
(‘Zackery’, ‘McEachern’, ‘[email protected]’) ;
INSERT INTO dbo.Customers (CustomerCompanyName, CustomerContactID, InvoiceAddressID, DeliveryAddressID)
VALUES
(‘Pitt and Co’, 1, 1, 2),
(‘Cooking Schmooking’, 2, 3, 4),
(‘Wilson Industries’, 3, 6, 6) ;
INSERT INTO dbo.SalesOrderHeaders (SalesOrderNumber, SalesOrderDate, SalesPersonID, SalesAreaID, CustomerID, SalesOrderDeliveryDueDate, SalesOrderDeliveryActualDate, CurrierUsedforDelivery)
VALUES
(‘COO1634D-U06’, ‘20230501’, 1, 1, 1, ‘20230503’, ‘20230503’, ‘LHD’),
(‘WIL1635D-E16’, ‘20230616’, 2, 2, 3, ‘20230630’, NULL, ‘GoodSpeed International’),
(‘PIT1636D-U04’, ‘20230616’, 3, 1, 1, ‘20230706’, NULL, ‘LHD’) ;
GO
CREATE NONCLUSTERED INDEX NI_SalesOrderHeaders_OrderDate ON SalesOrderHeaders(SalesOrderDate) ;
CREATE NONCLUSTERED INDEX NI_SalesOrderHeaders_SalesAreaID ON SalesOrderHeaders(SalesAreaID) ;
CREATE NONCLUSTERED INDEX NI_SalesOrderHeaders_CustomerID ON SalesOrderHeaders(CustomerID) ;
接下来,为了演示这个问题,我们需要查看刚刚创建的某个索引的索引页中存储了什么。这里我们使用 NI_SalesOrderHeaders_OrderDate 索引,但我们也可以选择任何我们喜欢的索引。
要查看索引页内部,需要三个步骤。第一步是确定我们索引的索引 ID。这不是在实例中唯一的对象 ID,而是表内的索引标识符。我们可以通过查询 sys.indexes 并按索引名称进行筛选,来列出给定索引的详细信息,如下面的示例所示。
SELECT
name
, index_id
, type_desc
FROM sys.indexes
WHERE name = ‘NI_SalesOrderHeaders_OrderDate’ ;
我拥有的索引 ID 是 2,但如果你以不同的顺序创建索引,你可能会发现 ID 不同。既然我们已经有了索引 ID,下一步是使用 DBCC IND 命令列出构成该索引的所有页面。
该命令列出了索引的 IAM 链,从根级一直到叶级。对于索引中的每一页都会返回一行,其中包括页码、索引级别以及用于遍历索引的页面指针,以及其他有用的信息。
该命令接受三个参数,即数据库名称(或数据库 ID)、表名称和索引 ID。下面的示例展示了如何使用此命令。
DBCC IND (‘MagicChoc’, ‘SalesOrderHeaders’, 2) ;
警告 我的结果如下所示,但请注意,您几乎肯定会发现您的页码有所不同。请确保在以下示例中使用您自己的页码。
结果如图 4.7 所示。你会注意到这里只有两页。第一页是索引的根页。无论索引大小如何,根页始终只有一个。由于索引太小,所以没有中间层。索引的叶子层正好由一页组成,因为表中只有三条记录,所以所有内容都可以轻松放入一页中。

最后一步是使用另一个 DBCC 命令,称为 DBCC PAGE。该命令可用于显示数据页或索引页的内容。该命令接受四个参数,分别是数据库名称、文件 ID、页 ID(来自 DBCC IND)以及指定格式选项的参数。然而,需要注意的是,在运行 DBCC PAGE 之前,我们必须确保追踪标志 3604 已开启。追踪标志用于开启或关闭功能,我们将在第 10 章讨论其中的一些。此特定标志会将 DBCC 输出发送到控制台。以下示例演示了如何使用该命令。
DBCC TRACEON(3604) ;
DBCC PAGE(‘MagicChoc’, 1, 600, 3) ;
我运行此命令的结果显示在图4.8中。如预期的那样,你会在SalesOrderDate(键)列中看到索引键值。但看看它旁边的列:SalesOrderNumber(键)列。主键的值存储在每一行中。这提供了指向聚集索引中数据的指针。

因此,主键不仅每行在表中占用 12 个字节,而且在表上每个非聚集索引的每行中最多也占用 12 个字节。更糟糕的是,我们的非聚集索引不是唯一的。如果非聚集索引是唯一的,那么聚集键值仅存储在索引的叶子层级。然而,对于非唯一的非聚集索引,聚集键值会存储在索引所有层级的每一行上。
这个宽键不仅使用额外的磁盘空间和内存,而且还会损害索引的性能。请记住,一个页面只能存储 8,000 字节的数据。因此,键越宽,需要的索引页面就越多。反过来,SQL Server 必须读取更多页面才能检索所需的数据。
在这种情况下,无论我们是发现自己的主键是一个宽列,还是主键是由多个列组成的复合键,我的建议是创建一个人工主键,并使用 IDENTITY 自动填充它。如果我们需要在自然键上强制唯一性,我们仍然可以做到,而无需通过在列上建立唯一非聚集索引来膨胀聚集和非聚集索引。
错误13# 未使用外键
缺少外键约束是我见过一些经验不足的开发者犯的错误,通常他们的理由是,如果需要快速向表中插入数据,约束会使过程过于耗时。我最常见这种观点出现的情况是在像我们这样的情形中,当键是自然键,因此具有业务意义并且由前端应用程序控制时。
这种思路的问题在于,前端应用程序无法像 SQL Server 约束那样保证数据的完整性。为了更详细地讨论这个话题,让我们使用我们的 PurchaseOrderHeaders 和 PurchaseOrderDetails 表作为例子。
您可能还记得,在清单 4.1 中,我们的数据库创建脚本中有一个错误,导致 PurchaseOrderDetails 表中存在 PurchaseOrderNumber 列,但由于未创建外键,因此无法与 PurchaseOrderHeaders 表进行关联。
在我们进一步操作之前,让我们运行下面清单中的脚本,将数据插入相关表中。
INSERT INTO dbo.ProductCategories (ProductCategoryName, ProductCategoryDescription)
VALUES
(‘Raw Ingridience’, NULL),
(‘Machine Parts’, ‘Parts used by manufacturing for machine maintenance’),
(‘Misc’, ‘Office supplies and other miscelaneous stock items’),
(‘Services’, ‘Non-stock purchases, such as transport’),
(‘Confectionary Products’, NULL),
(‘Non-confectionary Products’, NULL) ;
INSERT INTO dbo.ProductSubcategories (ProductCategoryID, ProductSubcategoryName, ProductSubcategoryDescription)
VALUES
(1, ‘Chilled Ingredience’, ‘Ingredience that must be kept between 1C and 5C’),
(1, ‘Frozen Ingredience’, ‘Ingredience must be kept below -18C’),
(1, ‘Ambient Ingredience’, ‘Ingredience that should be kept in cool, dry storage’),
(2, ‘Line 1 Components’, ‘Components required for manufacturing line 1’),
(2, ‘Line 2 Components’, ‘Components required for manufacturing line 1’),
(2, ‘Line 3 Components’, ‘Components required for manufacturing line 1’),
(2, ‘Line 4 Components’, ‘Components required for manufacturing line 1’),
(3, ‘Office Supplies’, ‘Stationary, etc’),
(3, ‘Misc’, NULL),
(4, ‘Curriers’, NULL),
(4, ‘Building Maintenance’, NULL),
(5, ‘Boxes of chocolates’, NULL),
(5, ‘Sweets’, NULL),
(5, ‘Chocolate Bars’, NULL),
(6, ‘Packaging’, ‘Product Packaging’),
(6, ‘Merchandise’, ‘Non-core items which are procured and sold, such as mugs and branded gifts’) ;
INSERT INTO dbo.ProductTypes (ProductTypeName, ProductTypeDescription)
VALUES
(‘Purchased Product’, ‘Products which are purchased’),
(‘Sold products’, ‘Products which are sold’),
(‘Traded Products’, ‘Products which are both bought and sold’) ;
INSERT INTO dbo.SupplierContacts (SupplierContactFirstName, SupplierContactLastName, SupplierContactEmail)
VALUES
(‘John’, ‘Smith’, ‘[email protected]’),
(‘John’, ‘Doe’, ‘[email protected]’),
(‘Michael’, ‘Knight’, ‘[email protected]’) ;
INSERT INTO dbo.Addresses (Street, City, ZipCode) –x3 suppliers
VALUES
(‘8648 Columbia Street’, ‘Beachwood’, ‘44122’),
(’83 Addison Dr.’, ‘Westerville’, ‘43081’),
(‘508 Mill Pond Street’, ‘Clinton Township’, ‘48035’) ;
INSERT INTO dbo.Suppliers (SupplierName, SupplierContactID, SupplierAddressID)
VALUES
(‘Smithfeilds’, 1, 7),
(‘Unknown Engineering’, 2, 8),
(‘Knight Rider Curriers’, 3, 9) ;
INSERT INTO dbo.Products (ProductName, ProductStockLevel, ProductTypeID, ProductSubcategoryID)
VALUES
(‘Large head sprocket’, 3, 1, 4),
(‘Long weight’, 6, 1, 4),
(‘Staples’, 8900, 1, 8),
(‘Magic Mug’, 38, 3, 16),
(‘Massive Magic Box’, 18, 2, 12),
(‘Delivery’, -1, 3, 10) ;
我们现在将模拟我们的前端应用程序使用清单 4.7 中的脚本将采购订单插入表中。该应用程序启用了 XACT_ABORT,并将两个 INSERT 语句都包装在事务中。这很好。这意味着如果一个语句失败,另一个也会失败,有助于保持数据的一致性。
SET XACT_ABORT ON ;
BEGIN TRANSACTION
SELECT @@TRANCOUNT ;
INSERT INTO dbo.PurchaseOrderHeaders (PurchaseOrderNumber, SupplierID, PurchaseOrderDate)
VALUES
(6826, 2, ‘20230601’),
(6827, 2, ‘20230617’) ;
INSERT INTO dbo.PurchaseOrderDetails (ProductID, Quantity, PurchaseOrderNumber)
VALUES
(4, 3, 6826),
(5, 4, 6827),
(4, 1, 6827) ;
COMMIT
但是,让我们考虑一下省略外键的原因:我们可能希望能够快速轻松地更新表。考虑以下情况。我们接到采购主管的电话,他说:“采购订单出了问题。应用程序不让我处理,我需要你在后台修复。我需要你把采购订单6827的订购商品移到采购订单6828上——马上!”
我们正承受压力,所以我们完全理性地,按照采购主管的要求,通过运行以下列表中的语句,做了他要求我们做的事情。
UPDATE dbo.PurchaseOrderDetails
SET PurchaseOrderNumber = 6828
WHERE PurchaseOrderNumber = 6827 ;
不幸的是,采购负责人真正希望我们做的是“创建一个新的采购订单,采购订单号为6828,将已订购的物品转移过去,然后删除采购订单6827。”
所以现在我们的数据处于不一致的状态。如果我们运行一个查询,例如清单 4.9 中的查询,它返回来自两个表的采购订单详情,那么采购订单 6827 和采购订单 6828 都不会被返回。
如果我们创建了外键约束,那么这是不可能的,因为会强制执行引用完整性,并且我们将无法将 PurchaseOrderNumber 更新为 PurchaseOrderHeaders 表中不存在的值。
SELECT
poh.PurchaseOrderNumber
, poh.PurchaseOrderDate
, pod.ProductID
, pod.Quantity
FROM dbo.PurchaseOrderHeaders poh
INNER JOIN dbo.PurchaseOrderDetails pod
ON poh.PurchaseOrderNumber = pod.PurchaseOrderNumber ;
为了避免这个陷阱,确保你始终使用外键约束。我们可以通过运行清单4.10中的脚本来修复MagicChoc数据库中的错误。在创建约束之前,我们先修复数据值;否则,创建约束将会失败。
UPDATE dbo.PurchaseOrderDetails
SET PurchaseOrderNumber = 6827
WHERE PurchaseOrderNumber = 6828 ;
ALTER TABLE dbo.PurchaseOrderDetails ADD CONSTRAINT
FK_PurchaseOrderDetails_PurchaseOrderHeaders FOREIGN KEY (PurchaseOrderNumber) REFERENCES dbo.PurchaseOrderHeaders(PurchaseOrderNumber) ;
当表之间存在关系时,创建主键和外键关系总是一个良好的做法。即使在应用程序中内置了逻辑来避免数据不一致,这些逻辑也无法处理发生在应用程序之外的错误。
总结
- 始终对你的数据进行规范化,而不是依靠判断来设计你的模式,以避免错误。
- 在适当的情况下,考虑使用数据泛化来创建超类型和子类型,因为这可以增强你的数据库设计。
- 使用ERD(实体关系图)来帮助验证并记录你的设计。该图将可视化实体及其属性,以及它们的主键和外键及其之间的关系。
- 避免使用宽列或多个列作为主键,因为主键通常会成为聚集索引,因此会在非聚集索引中被复制,可能导致性能下降。
- 在表相互关联时,始终使用外键约束,以避免数据一致性问题。



