第三章 数据类型
本章内容包括:
- 数据类型的重要性
- 使用错误标准数据类型的后果
- 使用高级数据类型的原因
- 处理 XML 和 JSON 数据的好处
错误6# 始终将整数存储为 INT
想象一下,我们有一个大型数据仓库。一个事实表有10亿行,并且与五个维度表关联,这些维度表各有30,000行。由于缓冲区缓存中的数据量大,性能很差且内存总是满的。当查询运行时,大量数据被写入TempDB。我们已经优化了查询,也已经审查了索引策略,并确保索引和统计信息都得到了良好的维护。看起来唯一能做的事情就是增加更多的硬件,但根据过去两年的趋势,我们怀疑如果增加更多的内存,只会将问题推到下一阶段。我们应该怎么做?一个起点是考虑审查我们的数值数据类型,特别是那些在主键/外键关系中使用的类型。
INT 是 SQL Server 中使用最广泛但也最容易被误用的数据类型。实际上,我们有四种专门用于存储整数的数据类型。这些数据类型在表中有详细说明。
整数类型
| Data type | Range | Size (Bytes) |
| TINYINT | 0 to 255 | 1 |
| SMALLINT | –32,768 to 32,767 | 2 |
| INT | –2,147,483,648 to 2,147,483,647 | 4 |
| BIGINT | –9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 | 8 |
SELECT
DATALENGTH(CAST(1 AS TINYINT)) AS TinyIntSize
, DATALENGTH(CAST(1 AS SMALLINT)) AS SmallIntSize
, DATALENGTH(CAST(1 AS INT)) AS IntSize
, DATALENGTH(CAST(1 AS BIGINT)) AS BigIntSize ;
TinyIntSize SmallIntSize IntSize BigIntSize
1 2 4 8
假设我们的五个维度表在其主键列中使用 INT 类型。每个维度表有 30,000 行,而 SMALLINT 数据类型可以表示的正值超过 32,000。这意味着如果我们预期维度不会大幅增长,那么我们可以在每行中节省 2 个字节。
此时,你可能会想,“我们为什么要在意节省2字节呢?”这个问题的答案需要一些简单的数学。每个五个维度表中都有30,000行。通过改用 SMALLINT,每个表我们只会节省 58 KB。但我们的事实表有 10 亿行。这意味着每个键可以节省 1.86 GB。将其乘以五个维度表,这意味着对于每个查询涉及事实表的所有行和所有五个键,我们将节省 9.3 GB。再将其扩展到数据仓库中的八个事实表。我们还应考虑索引的大小,这些索引是建立在这些外键列上的。现在考虑运行不同查询的并行会话。突然间,我们的数据类型选择对内存消耗产生了直接且显著的影响。
错误7# 始终使用可变长度字符串
想象一下,我们有一个存储美国地址的表。我们正努力确保数据尽可能节省空间。因此,我们对所有列使用可变长度字符串,包括地址的每一行以及邮政编码。我们知道缅因州的 Mooselookmeguntic 市和宾夕法尼亚州的 Kleinfeltersville 市拥有美国最长的城市名称,每个都有 17 个字符,所以我们将 CityName 列设置为 VARCHAR(17)。我们知道美国最长的州名是 Rhode Island and Providence Plantations,所以我们将 state 列设置为 VARCHAR(48)。我们知道邮政编码正好是 10 个字符,但因为我们知道每次长度都相同,我们应该使用 VARCHAR(10) 还是 CHAR(10)?这真的重要吗?无论哪种方式,数据长度都是 10 个字符,所以应该占用 10 个字节的空间,对吗?如果这是正确的,那么我们为什么还需要固定长度的字符串呢?事实是,这个假设并不正确。要理解原因,我们需要了解一些 SQL Server 是如何存储数据的。
SQL Server 将数据存储在一系列 8 KB 的页中,每八页组成一个 64 KB 的区块,这通常是读取的最小数据量。每个数据页都有一个 96 字节的页头,用于存储适用于整个页的信息,例如其唯一 ID 以及所属表(或索引)的对象 ID。
形成行的数据随后存储在页面上的槽中。然而,这些槽不仅存储数据。它们还必须存储少量元数据,以使数据有用。这些元数据包括关于存储在该槽中的记录类型的信息。例如,它是数据记录还是索引记录?它是否包含幽灵数据(已被逻辑删除但尚未实际移除的数据)?
其他元数据包括固定长度数据的长度(这不仅包括固定长度的字符数据,还包括整数等数据)、用于跟踪可变长度列是否包含 NULL 值的 NULL 值位图,以及版本标签,该标签用于诸如在线索引重建或具有乐观事务隔离级别的事务等操作。我们将在第 10 章讨论隔离级别。
然而,我们在这里真正关心的元数据部分是列偏移数组。它用于跟踪每个可变长度列在行中的起始位置。由于可变长度数据的长度可以是任意的,因此这个偏移表是 SQL Server 区分一段数据结束与下一段数据开始的唯一方式。
每个可变长度列在此表中都需要一个 2 字节的偏移量,这意味着每个可变长度列比固定长度列多使用 2 字节的空间。即使该列存储的是 NULL 值,这条规则仍然适用。因此,如果我们对邮政编码使用 CHAR(10),它将占用 10 字节的空间,但如果使用 VARCHAR(10),则会占用 12 字节的空间,尽管实际数据长度为 10 字节。
错误8# 编写你自己的层级代码
如果我们查看员工表,可能已经意识到 EmployeeID 和 ManagerID 列是用来表示员工层级的。因此,请参考图 3.2 中的组织架构图,它展示了 MagicChoc 高级管理团队的组织结构。
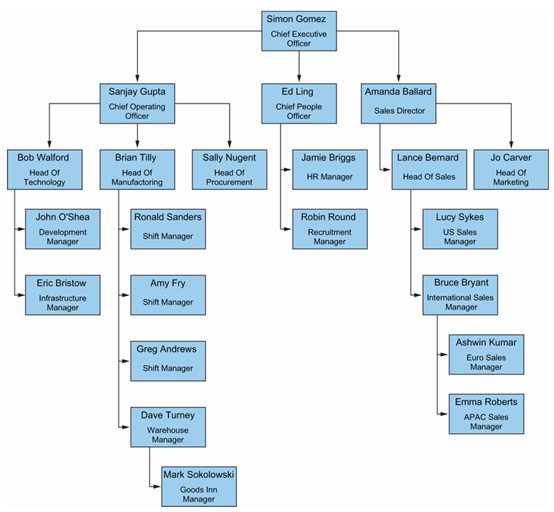
为了演示如何使用传统方法来建模这种层次结构——令人惊讶的是,仍有许多开发者在使用这种方法——我建议你运行清单 3.6 中的脚本,它会将员工记录插入到 Employees 表中。注意 ManagerID 列包含了他们所汇报的人的 EmployeeID。
INSERT INTO dbo.Employees (
EmployeeID
, FirstName
, LastName
, DateOfBirth
, EmployeeStartDate
, ManagerID
, Salary
, Department
, DepartmentCode
, Role
, WeeklyContractedHours
, StaffOrContract
, ContractEndDate
)
VALUES
(1, ‘Simon’, ‘Gomez’, ‘19691001’, ‘20180101’, NULL, 980000, ‘C-Suite’, ‘CS’, ‘CEO’, 40, 1, NULL),
(2, ‘Sanjay’, ‘Gupta’, ‘19761001’, ‘20180101’, 1, 640000, ‘C-Suite’, ‘CS’, ‘COO’, 40, 1, NULL),
(3, ‘Ed’, ‘Ling’, ‘19690403’, ‘20200801’, 1, 320000, ‘C-Suite’, ‘CS’, ‘CPO’, 40, 1, NULL),
(4, ‘Amanda’, ‘Ballard’, ‘19830401’, ‘20200301’, 1, 350000, ‘C-Suite’, ‘CS’, ‘Sales Director’, 40, 1, NULL),
(5, ‘Bob’, ‘Walford’, ‘19780908’, ‘20191201’, 2, 96000, ‘Technology’, ‘TE’, ‘Head Of Technology’, 40, 1, NULL),
(6, ‘Brian’, ‘Tilly’, ‘19710102’, ‘20181001’, 2, 89000, ‘Manufacturing’, ‘MA’, ‘Head Of Manufacturing’, 40, 1, NULL),
(7, ‘Sally’, ‘Nugent’, ‘19790302’, ‘20220601’, 2, 80000, ‘Procurement’, ‘PR’, ‘Head Of Procurement’, 40, 1, NULL),
(8, ‘Jamie’, ‘Briggs’, ‘19900102’, ‘20190601’, 3, 65000, ‘Human Resources’, ‘HR’, ‘HR Manager’, 40, 1, NULL),
(9, ‘Lance’, ‘Bernard’, ‘19910707’, ‘20210601’, 4, 98000, ‘Sales & Marketing’, ‘SA’, ‘Head Of Sales’, 40, 1, NULL),
(10, ‘Jo’, ‘Carver’, ‘19900810’, ‘20191201’, 4, 70000, ‘Sales & Marketing’, ‘SA’, ‘Head Of Marketing’, 40, 1, NULL),
(11, ‘John’, ‘O”Shea’, ‘19700609’, ‘20180601’, 5, 70000, ‘Technology’, ‘TE’, ‘Development Manager’, 40, 1, NULL),
(12, ‘Eric’, ‘Bristow’, ‘20000109’, ‘20221001’, 5, 72000, ‘Technology’, ‘TE’, ‘Infrastructure Manager’, 40, 1, NULL),
(13, ‘Ronald’, ‘Sanders’, ‘19601209’, ‘20190101’, 6, 45000, ‘Manufacturing’, ‘MA’, ‘Shift Manager’, 45, 1, NULL),
(14, ‘Amy’, ‘Fry’, ‘19921101’, ‘20190101’, 6, 45000, ‘Manufacturing’, ‘MA’, ‘Shift Manager’, 45, 1, NULL),
(15, ‘Greg’, ‘Andrews’, ‘19871212’, ‘20190101’, 6, 45000, ‘Manufacturing’, ‘MA’, ‘Shift Manager’, 45, 1, NULL),
(16, ‘Dave’, ‘Turney’, ‘19760609’, ‘20190101’, 6, 52000, ‘Manufacturing’, ‘MA’, ‘Warehouse Manager’, 48, 1, NULL),
(17, ‘Mark’, ‘Sokolowski’, ‘19960209’, ‘20190901’, 16, 42000, ‘Manufacturing’, ‘MA’, ‘Goods Inn Manager’, 40, 1, NULL),
(18, ‘Robin’, ‘Round’, ‘19940409’, ‘20190601’, 3, 60000, ‘Human Resources’, ‘HR’, ‘Recruitment Manager’, 40, 1, NULL),
(19, ‘Lucy’, ‘Sykes’, ‘19890201’, ‘20200201’, 9, 65000, ‘Sales’, ‘SA’, ‘US Sales Manager’, 40, 1, NULL),
(20, ‘Bruce’, ‘Bryant’, ‘19860304’, ‘20200301’, 9, 70000, ‘Sales’, ‘SA’, ‘International Sales Manager’, 40, 1, NULL),
(21, ‘Ashwin’, ‘Kumar’, ‘20010212’, ‘20210601’, 20, 55000, ‘Sales’, ‘SA’, ‘Euro Sales Manager’, 40, 1, NULL),
(22, ‘Emma’, ‘Roberts’, ‘20000208’, ‘20210601’, 20, 55000, ‘Sales’, ‘SA’, ‘APAC Sales Manager’, 40, 1, NULL) ;
现在假设我们被要求撰写一份报告,列出所有Sanjay Gupta的直接下属。这可以通过以下简单查询来实现:
SELECT
FirstName
, LastName
FROM dbo.Employees
WHERE ManagerID = 2 ;
但是,如果我们被要求编写一个查询,返回 Sanjay Gupta 的所有直接下属和间接下属呢?这就会变得更复杂。创建此报表有几种方法,包括令人畏惧的游标(我们将在第 5 章讨论),但最佳实践方法是开发人员使用递归公共表表达式(CTE)。CTE 是一个临时结果集,可以在查询中被多次引用。它也可以引用自身,从而实现递归。
递归是在这种情况下实现层级结构的关键。例如,列表 3.7 中的查询使用了一个公用表表达式(CTE)来返回所有直接和间接向 Sanjay Gupta 报告的员工记录,Sanjay Gupta 的 EmployeeID 为 2。在 CTE 的定义中,第一个查询返回 Sanjay 自己的员工记录。然后,UNION ALL 子句将第二个查询的结果追加上去。第二个查询是递归的,因为它将 Employees 表的结果与 CTE 中第一个查询的结果进行连接。由于连接是将第一个结果集中的 EmployeeID 与第二个结果集中的 ManagerID 相连,因此第二个结果集包含下属员工的详细信息。最终的 SELECT 语句位于 CTE 外部。它返回 CTE 中的所有记录,然后再次连接到底层的 Employees 表,以填充管理者的名字和姓氏。
DECLARE @ManagerID INT ;
SET @ManagerID = 2
;WITH EmployeeCTE AS (
SELECT
EmployeeId
, FirstName
, LastName
, ManagerId
FROM dbo.Employees
WHERE EmployeeId = @ManagerID
UNION ALL
SELECT
Emp.EmployeeId
, Emp.FirstName
, Emp.LastName
, Emp.ManagerId
FROM dbo.Employees AS Emp
INNER JOIN EmployeeCTE AS CTE
ON CTE.EmployeeId=Emp.ManagerId
)
SELECT
Emp.EmployeeID
, Emp.FirstName
, Emp.LastName
, Emp.ManagerID
, Mgr.FirstName AS ManagerFirstName
, Mgr.LastName AS ManagerLastName
FROM EmployeeCTE Emp
INNER JOIN dbo.Employees Mgr
ON Emp.ManagerID = Mgr.EmployeeID ;
另一个我们可能会被要求编写的典型查询涉及确定谁管理员工的经理。这在构建升级路径时很常见。清单 3.8 中的查询演示了如何确定 Emma Roberts 的经理的上级是谁。在此查询中,我们在 CTE 中的第一个查询中添加了一个常量 0,并为结果集指定了列名 Level,并指定 Emma Roberts 处于等级 0。然后递归查询会为层级中的每一层递增等级数。最后的查询(在 CTE 之外)根据等级 2 进行筛选,以返回比 Emma 高两级的实体。
DECLARE @EmployeeID INT ;
SET @EmployeeID = 22
; WITH EmployeeCTE AS
(
SELECT
employeeid
, firstname
, lastname
, managerid
, Role
, 0 as Level
FROM dbo.Employees
WHERE EmployeeID = @EmployeeID
UNION ALL
SELECT
emp.EmployeeID
, emp.FirstName
, emp.LastName
, emp.ManagerID
, emp.Role
, Level + 1
FROM dbo.employees emp
INNER JOIN EmployeeCTE cte
ON emp.EmployeeID = cte.ManagerID
)
SELECT
firstname
, lastname
, Role
FROM EmployeeCTE
WHERE Level = 2 ;
这种传统实现层级结构的方法的挑战在于,它要求开发者编写大量代码。本节中的示例比较简单,仅用于说明目的,但在实际场景中,递归CTE可能会变得复杂且难以管理。每当业务提出稍有不同的请求时,开发者都需要编写代码以以适当的方式遍历层级结构。例如,我们可能会被要求返回组织结构中第三级所有管理者的列表。
许多开发者没有意识到的是,微软已经为我们完成了大部分的艰难工作,即实现了 HIERARCHYID 数据类型。这是一种用 .NET 编写的高级数据类型,它允许我们对其调用方法,从而在不需要编写复杂的 CTE 的情况下遍历层次结构。
为了了解这是如何工作的,让我们在 Employees 表中添加一个新列,名为 ManagerHierarchyID,其类型将为 HIERARCHYID。我们可以使用以下清单中的脚本来实现这一点。
ALTER TABLE dbo.Employees ADD
ManagerHierarchyID HIERARCHYID NULL ;
为了利用 SQL Server 的层级功能,我们首先需要对层级进行建模。为了说明这种建模是如何工作的,请考虑我们组织结构图的以下部分。Simon Gomez 位于层级的顶端,我们将其称为根节点。
层级使用斜线格式建模。因此,层级的根表示为 /。Sanjay Gupta 和 Ed Ling 位于层级的第二层,每个人都需要被唯一标识。因此,Sanjay 将表示为 /1/,Ed 将表示为 /2/。
Jamie Briggs 和 Robin Round 都向 Ed Ling 汇报。因此,他们都处于层级的第三级,但也需要被唯一识别。因此,他们分别表示为 /1/2/1/ 和 /1/2/2/。层级从此继续构建。然后,它们以位字符串的形式存储在表中,并以十六进制值未经格式化的方式显示。例如,位于根级别的 Simon Gomez 的层级 ID 存储为 0x,而位于第二级的 Sanjay Gupta 存储为 0x58,Ed Ling 也在第二级,存储为 0x68。Jamie Briggs 和 Robin Round 分别存储为 0x6AC0 和 0x6B40。
但不要害怕:没有必要手动建模层级结构。相反,我们将采取两步法,这样可以减轻建模过程中的繁重工作。第一步是创建一个临时表,该表包含三列:EmployeeID、ManagerID,以及一个行号,我们将使用 ROW_NUMBER() 函数生成该行号,并按 ManagerID 对行号进行分区。该函数将为我们提供在层级分支的每个级别所需的递增数字。
第二步是定义一个基于我们的临时表的公用表达式(CTE),它将通过对 HIERARCHYID 类型使用 GetRoot() 全局方法来定义层级的根节点,针对位于层级顶端、因此 ManagerID 为 NULL 的 Simon Gomez。
递归查询将通过将下一个层级与我们使用 ROW_NUMBER() 生成的增量值连接来构建层次结构的后续级别。然后,我们可以使用 UPDATE 语句从 CTE 获取生成的层次结构 ID,并根据 EmployeeID 对 Employees 表进行更新。这在下面的示例中有演示。
SELECT
EmployeeID
, ManagerID
, ROW_NUMBER() OVER (PARTITION BY ManagerID ORDER BY ManagerID) AS Incremental
INTO #Hierachy
FROM dbo.Employees
;WITH HierarchyPathCTE AS (
SELECT
hierarchyid::GetRoot() AS ManagerHierarchyID
, EmployeeID
FROM #Hierachy AS C
WHERE ManagerID IS NULL
UNION ALL
SELECT
CAST(hpc.ManagerHierarchyID.ToString() + CAST(h.Incremental AS VARCHAR(30)) + ‘/’ AS HIERARCHYID)
,h.EmployeeID
FROM #Hierachy AS h
JOIN HierarchyPathCTE AS hpc
ON h.ManagerID = hpc.EmployeeID
)
UPDATE e
SET ManagerHierarchyID = hp.ManagerHierarchyID
FROM dbo.Employees e
INNER JOIN HierarchyPathCTE hp
ON e.EmployeeID = hp.EmployeeID ;
从这一点开始,处理层级变得非常简单。回想一下我们之前编写的查询,用于生成所有直接或间接向 Sanjay Gupta 汇报的人的列表。我们可以用下面清单中的简单查询替换整个递归查询,这个查询使用 IsDescendantOf() 方法,通过识别位于 Sanjay Gupta 所在层级分支中的任何人来过滤查询。
DECLARE @Manager HIERARCHYID ;
SELECT @Manager = ManagerHierarchyID
FROM dbo.Employees
WHERE EmployeeID = 2 ;
SELECT
EmployeeID
, FirstName
, LastName
, ManagerHierarchyID.ToString()
FROM dbo.Employees
WHERE ManagerHierarchyID.IsDescendantOf(@Manager) = 1 ;
以类似的方式,回想一下我们写的递归查询,用来查找谁管理Emma Robert的经理。这可以用下面清单中的简单脚本来替代,该脚本使用GetAncestor()方法来遍历层级结构。
DECLARE @EmployeeID INT ;
SET @EmployeeID = 22 ;
SELECT
FirstName
, LastName
, Role
, ManagerhierarchyID.ToString() AS ManagerHierarchyID
FROM dbo.Employees
WHERE ManagerHierarchyID = (
SELECT ManagerHierarchyID.GetAncestor(2)
FROM dbo.Employees
WHERE EmployeeID = @EmployeeID
) ;
你可能还记得,我曾提到我们可能会被要求以多种方式遍历层级结构,并暗示我们可能会遇到需要查找同层级同行的情况。为了探讨这有多简单,想象一下 MagicChoc 正在进行薪资基准调查。具体来说,Amy Fry 已经申请加薪,人力资源团队想知道她的薪资是否与组织中同级别的其他人相当。
在这种情况下,我们可以使用 GetLevel() 方法来确定她所在的层级,然后返回同一层级上所有其他员工的详细信息。这个技巧在以下示例中演示。
DECLARE @EmployeeID INT ;
SET @EmployeeID = 14 ;
SELECT
FirstName
, LastName
, Salary
FROM dbo.Employees
WHERE ManagerHierarchyID.GetLevel() = (
SELECT
ManagerHierarchyID.GetLevel()
FROM dbo.Employees
WHERE EmployeeID = @EmployeeID
) ;
错误9# 不将 XML 数据存储为原生 XML
当 XML 数据传递到数据库时,开发者常常觉得有必要将这些数据存储在关系型数据结构中。这有时出于对最佳实践的理解——既然这是数据库,那么以关系型格式存储数据肯定更好?有时则是因为害怕 XML,以及担心需要编写复杂的 XQuery 语句来访问数据。坦率地说,在许多情况下,将数据存储为关系型格式确实是个好主意,但在某些场景下情况并非如此。
让我们回忆一下我们的员工表。到目前为止,我们只为管理团队添加了员工记录,他们都是正式员工。然而,仓库经常通过一家名为 Total Warehouse Jobs 的招聘机构雇用临时员工。MagicChoc 与这家机构有大量业务往来,因此两家公司决定整合他们的系统。
当临时工离开MagicChoc时,他们的员工记录会从系统中删除。然而,Total Warehouse Jobs会保留他们过去合同的记录。如果某人和MagicChoc签订新合同,那么Total Warehouse Jobs需要提供他们以往合同的清单,以及他们所担任的职位。这有助于MagicChoc为他们分配适合其经验的工作。
XML 的特性意味着它具有可扩展性和可读性,支持模式验证,并且可以被普遍处理。这使它成为系统集成的热门选择。在我们的场景中,已达成一致,一旦合同签署,Total Warehouse Jobs 将以 XML 文档的形式发送员工之前合同的详细信息。这些信息需要存储在人力资源数据库中。
仓库应用程序每天使用这些数据来计算根据每日生产优先级将哪些人分配到哪些任务。ETL 过程需要以 XML 格式将数据发送到仓库应用程序。
拆解 XML
我看到一些开发人员处理这种情况的方式是将接收到的 XML 数据拆分到关系表中,然后重新构建一个 XML 文档发送给接收方。
如果我们在 MagicChoc 示例中采用这种方法,首先需要做的是创建一个用于存放历史合同数据的模式。由于数据的性质,我们将需要三个表来避免数据重复。这是规范化的一个关键概念,我们将在第四章讨论。下面的示例展示了该表可能的样子。
CREATE TABLE dbo.ContractHistory (
ContractHistoryID SMALLINT NOT NULL PRIMARY KEY IDENTITY,
EmployeeID SMALLINT NOT NULL REFERENCES dbo.Employees(EmployeeID),
ContractStartDate DATE NOT NULL,
ContractEndDate DATE NOT NULL
) ;
CREATE TABLE dbo.Skills (
SkillsID SMALLINT NOT NULL PRIMARY KEY IDENTITY,
Skill VARCHAR(30) NOT NULL
) ;
CREATE TABLE dbo.ContractSkills (
ContractSkillsID INT NOT NULL PRIMARY KEY IDENTITY,
ContractHistoryID SMALLINT NOT NULL REFERENCES dbo.ContractHistory(ContractHistoryID),
SkillID SMALLINT NOT NULL REFERENCES dbo.Skills(SkillsID)
) ;
因为我们刚创建的技能表是一个参考表,在继续之前,让我们使用以下清单中的脚本添加一些示例数据。
INSERT INTO dbo.Skills (Skill)
VALUES
(‘Picker’),
(‘Packer’),
(‘Stock Take’),
(‘Forklift Driver’),
(‘Machine 1 operator’),
(‘Machine 2 operator’),
(‘Machine 3 operator’),
(‘Machine 4 operator’) ;
历史合同数据由一个以元素为中心的 XML 文档组成,根元素称为 <EmployeeContracts>。
在根元素下面,有一个名为< Employee >的复杂元素,其中包含将在我们的Employees表中存储的子元素。它还包含一个名为< Contracts >的嵌套复杂元素,该元素包含一个重复元素< Contract >,其中包含每个员工所拥有的每份合同的详细信息。在< Contract >下还嵌套了一个更复杂的元素,称为< Skills >,其中又包含一个重复元素< Skill >。我们从Total Warehouse Jobs收到的数据示例如下:
<EmployeeContracts>
<Employee>
<EmployeeID>23</EmployeeID>
<FirstName>Robert</FirstName>
<LastName>Blake</LastName>
<DateOfBirth>19781212</DateOfBirth>
<Contracts>
<Contract>
<StartDate>20200101</StartDate>
<EndDate>20203006</EndDate>
<Skills>
<Skill>Forklift driver</Skill>
<Skill>Picker</Skill>
<Skill>Packer</Skill>
</Skills>
</Contract>
<Contract>
<StartDate>20210101</StartDate>
<EndDate>20211212</EndDate>
<Skills>
<Skill>Picker</Skill>
<Skill>Stock Take</Skill>
</Skills>
</Contract>
</Contracts>
</Employee>
</EmployeeContracts>
因此,要使用将此数据集存储在传统关系结构中的方法,我们的第一步是拆分接收到的数据。为此,我们可以使用 OPENXML() 函数,该函数会从 XML 文档返回一个行集,也可以使用 nodes() 和 value() XQuery 方法的组合。在这个示例中,我们将使用 OPENXML(),因为这是我最常看到人们使用的方法。
使用 OPENXML() 函数的第一个复杂性在于它没有内置的 XML 解析器。相反,我们必须在将 XML 文档传递给该函数之前,使用 MSXML 解析器解析它。我们可以通过使用 sp_xml_preparedocument 存储过程来执行文档准备。该过程将解析文档,输出对象将包含指向文档中节点的内存树表示的句柄,然后可以将其传递给函数。
我们还需要传递 OPENXML() 函数,一个用于标识要处理行的 XPath 模式。我们将把这个 XPath 表达式指向层次结构的最低级别,然后在映射中使用 ../ 运算符来遍历更高级别。
最后一个参数是可选的,用于指示如何填充溢出列。可能的值在表 3.2 中有详细说明。
| Value | Description |
| 0 | Attribute-centric mapping |
| 1 | Applies attribute-centric mapping followed by element-centric mapping |
| 2 | Applies element-centric mapping followed by attribute-centric mapping |
| 8 | Does not copy data to the overflow property |
WITH 子句与 OPENXML() 一起使用,用于指定文档中节点的数据类型和映射。如果省略 WITH 子句,则 SQL Server 会返回一个 XML 边表,详细列出文档的细粒度结构信息,包括命名空间 URI、命名空间前缀,以及指向下一个和上一个兄弟元素的指针。
清单 3.16 中的脚本演示了将数据拆解并插入到表中的过程可能是什么样子。我们首先做的是声明变量来存储原始的 XML 文档以及准备文档的内存解析树的句柄。接下来是两个表变量。第一个将存储 OPENXML() 函数的结果,而第二个只是保存一些我们模拟从人力资源应用程序中提取的内部员工数据,这些数据用于填充 Employees 表。接下来,我们在调用 OPENXML() 函数之前解析 XML 数据,并将结果插入到表变量中。之后,我们运行查询以复制数据并插入到表中。这些 INSERT 语句被包装在一个事务中(将在第 10 章讨论),这意味着如果其中一个插入操作失败,所有插入都将回滚。这可以防止我们在表之间出现不一致的数据,从而在失败时需要手动处理。在事务开始之前,已经启用了 XACT_ABORT。即使语句只是因轻微错误(例如外键约束失败)而失败,这也会阻止事务继续执行。
DECLARE @RawContractDetails XML ;
DECLARE @ParsedContractDetails INT ;
DECLARE @ShreddedData TABLE (
EmployeeID INT
, FirstName NVARCHAR(32)
, LastName NVARCHAR(32)
, DateOfBirth DATE
, ContractStartDate DATE
, ContractEndDate DATE
, Skill NVARCHAR(30)
) ;
DECLARE @InternalEmployeeData TABLE (
EmployeeStartDate DATE
, ManagerID SMALLINT
, Salary MONEY
, Department NVARCHAR(64)
, DepartmentCode NCHAR(2)
, Role NVARCHAR(64)
, WeeklyContractedHours INT
, StaffOrContract BIT
, ContractEndDate DATE
, ManagerHierarchyID HIERARCHYID
) ;
INSERT INTO @InternalEmployeeData
VALUES (‘20230101’, 14, 39000, ‘Manufacturing’, ‘MA’, ‘Warehouse Operative’, 40, 0, ‘20231231’, ‘/1/2/2/1/’) ;
SET @RawContractDetails = N'<EmployeeContracts>
<Employee>
<EmployeeID>23</EmployeeID>
<FirstName>Robert</FirstName>
<LastName>Blake</LastName>
<DateOfBirth>19781212</DateOfBirth>
<Contracts>
<Contract>
<StartDate>20200101</StartDate>
<EndDate>20200603</EndDate>
<Skills>
<Skill>Forklift driver</Skill>
<Skill>Picker</Skill>
<Skill>Packer</Skill>
</Skills>
</Contract>
<Contract>
<StartDate>20210101</StartDate>
<EndDate>20211231</EndDate>
<Skills>
<Skill>Picker</Skill>
<Skill>Stock Take</Skill>
</Skills>
</Contract>
</Contracts>
</Employee>
</EmployeeContracts>’ ;
EXEC sp_xml_preparedocument @ParsedContractDetails OUTPUT, @RawContractDetails ;
INSERT INTO @ShreddedData #D
SELECT *
FROM OPENXML(@ParsedContractDetails, ‘/EmployeeContracts/Employee/Contracts/Contract/Skills/Skill’, 2)
WITH (
EmployeeID SMALLINT ‘../../../../EmployeeID’,
FirstName NVARCHAR(32) ‘../../../../FirstName’,
LastName NVARCHAR(32) ‘../../../../LastName’,
DateOfBirth DATE ‘../../../../DateOfBirth’,
ContractStartDate DATE ‘../../StartDate’,
ContractEndDate DATE ‘../../EndDate’,
Skill NVARCHAR(30) ‘text()’
) ;
SET XACT_ABORT ON ;
BEGIN TRANSACTION
INSERT INTO dbo.Employees
SELECT
s.EmployeeID
, s.FirstName
, s.LastName
, s.DateOfBirth
, i.EmployeeStartDate
, i.ManagerID
, i.Salary
, i.Department
, i.DepartmentCode
, i.Role
, i.WeeklyContractedHours
, i.StaffOrContract
, i.ContractEndDate
, i.ManagerHierarchyID
FROM @ShreddedData s
INNER JOIN @InternalEmployeeData i
ON 1=1
GROUP BY
s.EmployeeID
, s.FirstName
, s.LastName
, s.DateOfBirth
, i.EmployeeStartDate
, i.ManagerID
, i.Salary
, i.Department
, i.DepartmentCode
, i.Role
, i.WeeklyContractedHours
, i.StaffOrContract
, i.ContractEndDate
, i.ManagerHierarchyID ;
INSERT INTO dbo.ContractHistory(EmployeeID, ContractStartDate, ContractEndDate)
SELECT
EmployeeID
, ContractStartDate
, ContractEndDate
FROM @ShreddedData
GROUP BY
EmployeeID
, ContractStartDate
, ContractEndDate ;
INSERT INTO dbo.ContractSkills(ContractHistoryID, SkillID)
SELECT
ch.ContractHistoryID
, s.SkillsID
FROM @ShreddedData sd
INNER JOIN dbo.Skills s
ON TRIM(s.Skill) = TRIM(sd.Skill)
INNER JOIN dbo.ContractHistory ch
ON sd.EmployeeID = ch.EmployeeID
AND sd.ContractStartDate = ch.ContractStartDate
AND sd.ContractEndDate = ch.ContractEndDate ;
COMMIT
EXEC sp_xml_removedocument @ParsedContractDetails ;
好吧,那确实是辛苦的工作,对吧?对 SQL Server 来说也是如此!在我的实验环境中,这是一个 t2.large EC2 实例,只运行这个脚本,执行该脚本花费了 31 毫秒。也就是说,将五行数据处理成三个表只用了 31 毫秒。到目前为止,我们所做的只是拆分数据。在下一部分,我们将看一下重新构建 XML 文档的过程,以便将其发送给客户端。也许你开始明白为什么我不推荐在我们的特定用例中使用这种方法了。
重建 XML
现在我们已经将 XML 数据拆分成表格,我们需要编写 ETL 用于将数据发送到仓库应用程序的过程。这意味着需要从存储在表格中的数据重建 XML 文档。我们可以通过使用带有 FOR XML 子句的 SELECT 语句来实现这一点。FOR XML 有四种可能的模式,这些模式在表 3.3 中有详细说明。
模式 说明
RAW 构建 XML 的最基本模式。它生成一个平铺的 XML 文档,每行对应一个元素。
AUTO 生成带嵌套元素的 XML 文档。嵌套由查询中的连接条件控制。自动格式化意味着我们对 XML 的格式控制非常有限。
PATH 通过将查询中的列映射到层次结构中指定位置的 XML 节点,可以高级控制 XML 文档的格式。
EXPLICIT 提供与 PATH 模式类似的格式控制,但过于复杂。通常不需要使用此模式。
为了为我们的 XML 文档创建正确的结构,我们需要使用 FOR XML PATH,并结合使用子查询,子查询也使用 FOR XML PATH 子句。需要子查询的原因是为了处理文档子级中重复的元素。
列表 3.17 中的查询演示了我们如何通过使用两层子查询来实现这一点。最内层的查询返回与给定合同相关的技能。这些结果使用 FOR XML PATH 转换为 XML。此子句使用 TYPE 关键字来定义结果将是格式良好的 XML,并使用 ROOT 指定文档中根节点的名称。外层子查询使用相同的过程从重复的 Contracts 元素中提取详细信息。最后,外层查询返回员工详细信息,这些信息将位于层级结构的顶端。
SELECT
e.EmployeeID ‘EmployeeID’
, e.FirstName ‘FirstName’
, e.LastName ‘LastName’
, e.DateOfBirth ‘DateOfBirth’
, (
SELECT
ch.ContractStartDate ‘StartDate’
, ch.ContractEndDate ‘EndDate’
, (
SELECT
s.Skill ‘Skill’
FROM dbo.Skills s
INNER JOIN dbo.ContractSkills cs
ON s.SkillsID = cs.SkillID
WHERE cs.ContractHistoryID = ch.ContractHistoryID
FOR XML PATH(”), TYPE, ROOT(‘Skills’)
)
FROM dbo.ContractHistory ch
WHERE EmployeeID = e.EmployeeID
FOR XML PATH(‘Contract’), TYPE, ROOT(‘Contracts’)
)
FROM dbo.Employees e
WHERE EmployeeID = 23
FOR XML PATH(‘Employee’), ROOT(‘EmployeeContracts’) ;
在我的实验室环境中,这个查询花了52毫秒完成。现在想象一下在生产环境中,这些过程被多人不断运行。再想想这些过程需要在大型复杂的XML文档上运行的情况。你可以理解为什么这可能会变得相当昂贵。
通过将数据存储为 XML 来避免开销
将 XML 转换为关系数据再转换回去花费了相当多的努力,并且总共耗时 83 毫秒。如果我们以 XML 格式存储数据,本可以节省开发时间以及编译/执行时间。那么,让我们来探讨如果以原生格式存储数据,对开发和处理会产生什么影响。
由于员工的技能和合同的所有详细信息都存储在单个 XML 文档中,因此不需要 EmployeeContracts 和 EmployeeSkills 表。相反,我们可以直接将 XML 文档插入到 Employees 表中。在开始之前,让我们更新 Employees 表并添加一个名为 PreviousContracts 的列,用于存储这些数据。下面的示例包含了一个我们可以运行以实现此目的的命令。
ALTER TABLE dbo.Employees
ADD PreviousContracts XML NULL ;
在我们的具体场景中,我们无法避免使用少量的 XQuery。这是因为数据将基于 EmployeeID 进行键控,而该 ID 是由 XML 文档中的 Total Warehouse Jobs 提供的。因此,我们需要提取此值以及员工的姓名和出生日期。
在清单 3.19 中演示了一个可以用来将新用户添加到 Employees 表的脚本。与前面的例子一样,我们使用一个名为 @InternalEmployeeData 的表变量来模拟我们的 HR 系统,以提供一些将填充 Employees 表的值。然后,我们使用 XQuery 的 value() 方法从 XML 文档中提取 EmployeeID、FirstName、LastName 和 DateOfBirth 节点。value() 方法传入要提取节点的 XPath,以及节点将映射到的 SQL Server 数据类型。value() 需要一个单一的值,因此即使节点不重复,也必须指定所需的节点索引。请注意,XML 文档中的 EmployeeID 已被递增,以避免由于违反主键约束而导致插入失败。
DECLARE @RawContractDetails XML ;
DECLARE @InternalEmployeeData TABLE (
EmployeeStartDate DATE
, ManagerID SMALLINT
, Salary MONEY
, Department NVARCHAR(64)
, DepartmentCode NCHAR(2)
, Role NVARCHAR(64)
, WeeklyContractedHours INT
, StaffOrContract BIT
, ContractEndDate DATE
, ManagerHierarchyID HIERARCHYID
) ;
INSERT INTO @InternalEmployeeData
VALUES (‘20230101’, 14, 39000, ‘Manufacturing’, ‘MA’, ‘Warehouse Operative’, 40, 0, ‘20231231’, ‘/1/2/2/1/’) ;
SET @RawContractDetails = N'<EmployeeContracts>
<Employee>
<EmployeeID>25</EmployeeID>
<FirstName>Robert</FirstName>
<LastName>Blake</LastName>
<DateOfBirth>19781212</DateOfBirth>
<Contracts>
<Contract>
<StartDate>20200101</StartDate>
<EndDate>20200603</EndDate>
<Skills>
<Skill>Forklift driver</Skill>
<Skill>Picker</Skill>
<Skill>Packer</Skill>
</Skills>
</Contract>
<Contract>
<StartDate>20210101</StartDate>
<EndDate>20211231</EndDate>
<Skills>
<Skill>Picker</Skill>
<Skill>Stock Take</Skill>
</Skills>
</Contract>
</Contracts>
</Employee>
</EmployeeContracts>’ ;
INSERT INTO dbo.Employees
SELECT
@RawContractDetails.value(‘(/EmployeeContracts/Employee/EmployeeID)[1]’, ‘SMALLINT’) AS EmployeeID
,@RawContractDetails.value(‘(/EmployeeContracts/Employee/FirstName)[1]’, ‘NVARCHAR(32)’) AS FirstName
,@RawContractDetails.value(‘(/EmployeeContracts/Employee/LastName)[1]’, ‘NVARCHAR(32)’) AS LastName
,@RawContractDetails.value(‘(/EmployeeContracts/Employee/DateOfBirth)[1]’, ‘DATE’) AS DateOfBirth
, EmployeeStartDate
, ManagerID
, Salary
, Department
, DepartmentCode
, Role
, WeeklyContractedHours
, StaffOrContract
, ContractEndDate
, ManagerHierarchyID
, @RawContractDetails AS PreviousContracts
FROM @InternalEmployeeData ;
在我的实验环境中,这个脚本执行花费了33毫秒。我们现在可以使用下面列表中的简单SELECT语句来检索仓库应用程序的XML文档。
SELECT
PreviousContracts
FROM dbo.Employees
WHERE EmployeeID = 25 ;
在我的实验环境中,这条 SELECT 语句的执行时间不到 1 毫秒。如果我们四舍五入到 1 毫秒,这意味着插入操作和 XML 数据返回的总耗时为 34 毫秒。这意味着,总体而言,当我们避免拆分(shredding)时,端到端的处理速度提高了两倍以上。
这是否意味着我们永远不应该拆分XML数据?不,绝对不是!拆分数据有很多合理的理由。我通常遵循的一个通用原则是,T-SQL比XQuery高效得多。因此,如果我们的场景需要我们频繁查询数据,那么拆分数据是个好主意。相反,如果我们经常写入数据但很少查询,那么以原生XML格式存储数据是最佳方法。我们应该避免的错误是总是拆分数据(或者,同样的,总是以XML存储数据)。相反,应根据应用的需求来做设计决定。
错误10# 忽略 JSON
正如SQL开发人员倾向于避免使用XML数据一样,他们也倾向于避免使用JSON数据。正如我们在讨论XML时看到的,这可能导致表设计不理想和性能不佳。让我们假设我们被要求扩展员工实体的数据模式,以便可以存储他们的家庭地址。
在 SQL Server 中建模地址的典型模型是创建一个 Addresses 表,使用 AddressID 作为主键,然后在 Employees 表以及其他可能涉及地址的表(例如 HR 数据库中的 Offices 或 Sites)中也有一个同名列。Employees 表中的这一列将会有外键约束,以确保只能存储 Addresses 表中的有效值。
这个模型可以,但它会变成一个宽而稀疏的表,因为并非所有地址都有相同数量的行,而且我们需要能够处理任何可能的情况。在 MagicChoc 的情况下,这种情况更为严重,因为它是一家国际公司。想想邮政编码吧。在英国,它们被称为邮编,在泰国是 yóu dì qū hào,在巴林是区号,仅举几例。由于在不同国家的格式不同,我们要么将这些存储在非常宽松的数据类型中,要么为每个国家使用独立、稀疏的列。还值得注意的是,许多国家,如巴哈马、多米尼加、斐济以及许多非洲国家,并没有邮政编码的对应物,这进一步增加了表的稀疏性。
根据我们的应用需求,更好的数据设计可能是将数据存储为 JSON 格式。像 XML 一样,JSON 具有半结构化的格式,可以省略不相关的数据。它越来越受欢迎,因为它是一种非常轻量的格式,标签比 XML 少得多。
由于 T-SQL 在查询数据方面的高效性,当我在进行数据建模时,我对 JSON 的处理规则与对 XML 的处理规则相同。也就是说,如果数据写入频繁而查询不频繁,那么 JSON 是一个不错的选择。然而,如果数据被查询的频率远高于写入的频率,那么我更倾向于以关系型方式存储数据。
JSON 的其他使用场景包括建模那些原本需要在关系型数据和 NoSQL 之间拆分的数据域。这是因为,在 SQL Server 中,两种类型的数据可以存储在相同的模式中,从而支持与采用 JSON 格式发送和接收数据的 REST API 或其他系统集成进行通信。现在,在 SQL Server 中存储和分析基于 JSON 的日志数据也变得可行。
那么让我们看看如何通过将员工地址数据建模为 JSON 格式来避免忽略 JSON 的错误。如果我们的地址可能与多个实体相关,例如办公室或站点,那么我们可能仍然希望建立一个 Addresses 表,以便 JSON 格式的地址可以被多个实体使用。然而,我们确信 Employees 是唯一需要与地址数据交互的实体,因此我们将在 Employees 表中添加一个额外的列来存储地址数据。下面的列表显示了一个将创建该列的命令。
ALTER TABLE dbo.Employees
ADD Address NVARCHAR(MAX) ;
注意,但请等一下!我们将用 JSON 对数据建模,那么为什么我们刚刚创建了一个 NVARCHAR(MAX) 类型的列呢?答案是,截至撰写本文时,Azure SQL 数据库中 JSON 数据类型仍在预览阶段,但对于 IaaS 或本地的 SQL Server,JSON 并没有自己的数据类型。它以 VARCHAR 或 NVARCHAR 存储,然后作为文本进行索引。这使得 JSON 与任何支持文本的 SQL Server 功能完全兼容。
首先,让我们来看一下用于存储地址的 JSON 文档的格式。JSON 格式使用简单的 名称:值 对,用””括起来。嵌套使用 {} 表示。使用 [] 表示一个数组。我们的地址文档以 EmployeeAddress 为根,包含 EmployeeID 和 Address 节点。Address 节点下还有进一步的子节点,用于存储地址的每一行。根据每个地址的需求,可以添加额外的行或替换现有节点,这意味着我们消除了稀疏数据的问题。示例文档如下:
{
“EmployeeAddress”:[
{
“EmployeeID”:1,
“Address”:{
“Line1″:”5331 Rexford Court”,
“City”:”Montgomery”,
“State”:”AL”,
“ZipCode”:”36116″
}
}
]
}
我们可以使用带有 FOR JSON 子句的 SELECT 语句生成此文档。有两种 FOR JSON 处理选项:AUTO 和 PATH。AUTO 可以根据列的顺序和表连接顺序自动格式化文档。PATH 模式则可以对格式进行更精细的控制。
小技巧:JSON AUTO 只能用于表,因此理论上它不能以我们计划的方式使用,但通过向任意表添加 FROM 子句可以轻松绕过这一限制。我通常使用 sys.tables 来实现这一目的,但任何表都可以。如果使用这种技巧,我们需要在 SELECT 子句中添加 TOP 1,以避免为表中的每条记录返回一个节点。
列表 3.22 中的查询将生成我们的示例 JSON 文档。请注意,我们使用的是 PATH 模式,因此每一列都有一个别名,用于指定节点的名称及其在 JSON 层次结构中的位置。
SELECT
1 AS ‘EmployeeID’
, ‘5331 Rexford Court’ AS ‘Address.Line1’
, ‘Montgomery’ AS ‘Address.City’
, ‘AL’ AS ‘Address.State’
, ‘36116’ AS ‘Address.ZipCode’
FOR JSON PATH, ROOT (‘EmployeeAddress’) ;
列表 3.23 中的脚本演示了如果我们以 JSON 格式获得地址数据,如何更新 Employees 表以添加员工地址。UPDATE 语句的 WHERE 子句使用 JSON_VALUE() 函数从文档中检索 EmployeeID。该函数接受的第一个参数是要搜索的 JSON 文档。第二个参数指定节点的路径。JSON 路径总是以 $. 开头,表示整个文档。根节点 EmployeeAddress 是一个数组(用方括号表示),意味着我们需要传递数组索引来指定希望返回值的记录。如果不传递该索引,即使只有一条记录(如我们的示例中),也将返回 NULL 结果。
DECLARE @EmployeeAddress NVARCHAR(MAX) ;
SET @EmployeeAddress = (
SELECT
1 AS ‘EmployeeID’
, ‘5331 Rexford Court’ AS ‘Address.Line1’
, ‘Montgomery’ AS ‘Address.City’
, ‘AL’ AS ‘Address.State’
, ‘36116’ AS ‘Address.ZipCode’
FOR JSON PATH, ROOT (‘EmployeeAddress’)
) ;
UPDATE dbo.Employees
SET Address = @EmployeeAddress
WHERE EmployeeID =
JSON_VALUE(@EmployeeAddress, ‘$.EmployeeAddress[0].EmployeeID’) ;
如果我们需要将这个 JSON 文档拆分成关系型格式,那么我们可以使用 OPENJSON() 函数。对于那些在本章前面阅读过 OPENXML() 的人来说,OPENJSON() 的格式和功能会显得很熟悉。不过,OPENJSON() 函数的优势在于,无需在使用前准备文档。这可以节省资源使用。
在示例 3.24 中,我们使用 OPENJSON() 函数来解析我们的员工地址文档。传递给该函数的第一个参数是 JSON 文档本身。第二个参数指定我们希望查询的层级中最高级别的路径。请记住,$ 表示整个文档,就像我们使用 JSON_VALUE() 时一样,我们传递的路径需要考虑数组,通过指定数组索引来处理。WITH 子句指定我们希望从文档中返回的列,以及它们将映射到的 SQL 数据类型和相关节点的路径,当节点不在与路径表达式相同的级别时也适用。
DECLARE @EmployeeAddress NVARCHAR(MAX) ;
SET @EmployeeAddress = (
SELECT
1 AS ‘EmployeeID’
, ‘5331 Rexford Court’ AS ‘Address.Line1’
, ‘Montgomery’ AS ‘Address.City’
, ‘AL’ AS ‘Address.State’
, ‘36116’ AS ‘Address.ZipCode’
FOR JSON PATH, ROOT (‘EmployeeAddress’)
) ;
SELECT *
FROM OPENJSON(@EmployeeAddress, ‘$.EmployeeAddress[0]’)
WITH (
EmployeeID SMALLINT,
Line1 NVARCHAR(64) ‘$.Address.Line1’,
City NVARCHAR(64) ‘$.Address.City’,
[State] NCHAR(2) ‘$.Address.State’,
ZipCode NVARCHAR(10) ‘$.Address.ZipCode’
) ;
我们可以看到,如果使用得当,JSON 在 SQL Server 中可以发挥重要作用。我们可以利用 SQL Server 的 JSON 支持来去规范化数据并简化复杂的数据模型,集成 NoSQL,或者避免处理从 API 发送和接收的数据。
总结
- 始终使用最严格的数据类型,以便能够存储所有可能需要的值。这对于用于关键约束的整数值或被索引的值尤其重要。
- 当列中字符串长度一致时,总是使用固定长度的字符串以减少存储开销。当长度不一致时,总是使用可变长度的字符串。
- 在建模和创建层次结构时,避免编写自己的代码或创建自引用表。相反,应使用 HIERARCHYID 数据类型,因为该类型包含多种方法,可以减轻开发负担。
- 当我们面对 XML 数据时,不必总是将这些数据拆分到关系模型中。始终考虑应用程序需求,并据此建模数据模式。这可能包括或不包括以原生 XML 存储数据。
- 也不要回避使用 JSON 数据。在某些情况下,使用 JSON 数据可以简化数据模型,是一个不错的选择。



